
Welcome to Edition 3 of Fine-Tuned by Genloop – your guide to the evolving world of LLM customization.
The past two weeks have been nothing short of a movie. DeepSeek has revolutionized the industry with its newest model DeepSeek-R1, delivering exceptional reasoning performance at a fraction of the usual cost. The best thing - it is open-weight and comes with distilled versions. The impact was so significant that it overshadowed OpenAI's release of Operator, their response to Anthropic's Computer Use. The pace of GenAI developments is breathtaking, leaving everyone eager to see what comes next!
In this edition, we'll explore these groundbreaking developments and highlight the key updates you need to stay informed.
🌟 AI Industry Highlights
1. DeepSeek R1 After-Effects
DeepSeek's R1 model has shaken up the AI landscape. Trained for under $6M (disputed), it rivals OpenAI's models while pioneering open-source reasoning and an RL-based reward system. The impact has been massive—R1 has elevated China’s AI standing, triggered geopolitical tensions, and even wiped $1T off US stocks in what some call AI’s ‘Sputnik Moment.’ In response, OpenAI’s Sam Altman admitted the need to rethink their open-source approach.
Key Points:
Competitive Pressure: R1 challenges closed-source AI, forcing companies like OpenAI to adjust.
Market Reassessment: AI stock valuations are shifting due to DeepSeek’s emergence.
Enterprise Implications: Businesses can now fine-tune reasoning models for their needs.
We broke down DeepSeek R1 in #TuesdayPaperThoughts Edition 21—check it here.
2. NVIDIA Stock Plummets Amid DeepSeek's Breakthrough
NVIDIA’s stock has seen sharp swings, dropping 14% year-to-date, largely due to concerns over DeepSeek’s low-cost AI training disrupting the GPU market. On January 27, 2025, NVIDIA suffered a historic 17% drop, wiping out $595B in market cap—the largest single-day loss in corporate history.
That said, NVIDIA isn’t doomed. While AI compute costs may fall, the Jevons Paradox suggests that cheaper computing could boost overall GPU demand, creating a positive feedback loop for adoption.
Key Points:
Investor Uncertainty: DeepSeek’s breakthrough raises questions about GPU demand.
Historic Market Loss: NVIDIA lost $595B in a single day, the worst in history.
Jevons Paradox Effect: Lower AI compute costs could still drive higher GPU adoption.

3. OpenAI Deep Research vs Gemini Deep Research
OpenAI recently released an OpenAI Deep research, integrated in ChatGPT Pro, offering advanced reasoning capabilities and methodical research processes. It was natural to compare it with Google’s Gemini Deep Research, and here is the verdict.
Key Points
OpenAI Deep Research is more advanced and expert, Google Gemini is faster and more structured
OpenAI Deep Research is multi-modal, and Google Gemini is text-focused
OpenAI Deep Research is $200/month, Google Gemini is $20/month
4. Softbank to spend 3B$ on OpenAI Tech
SoftBank is committing $3 billion annually to OpenAI for access to ChatGPT Enterprise, custom models, and new AI products like Operator and Deep Research. This partnership includes a joint venture, SB OpenAI Japan, to market OpenAI’s enterprise tech in Japan. Meanwhile, OpenAI is reportedly in talks to raise up to $40 billion, with SoftBank potentially leading the round.
Key Points:
$3B/year Deal: SoftBank will use OpenAI's tech across its subsidiaries.
New JV: "SB OpenAI Japan" will sell OpenAI’s enterprise solutions in Japan.
Mega Funding Round: OpenAI aims to raise $40B, with SoftBank possibly investing $15-25B.
📚 Featured Blog Posts
We've got two fascinating reads that showcase how the AI landscape is evolving
1. Devin vs Enterprise Reality

In a recent analysis, Hamel H. provides a sobering perspective on Devin, a heavily promoted AI software engineering tool, highlighting the gap between flashy demos and practical enterprise applications.
Key points:
Demo vs Reality Gap: While impressive demos catch attention, they rarely translate to consistent real-world performance, especially in complex enterprise environments
Enterprise AI Pyramid: The AI startup landscape resembles a pyramid - numerous demo projects at the bottom, fewer truly usable applications in the middle, and rare enterprise solutions requiring deep domain expertise at the top.
Implementation Hurdles: Moving from cherry-picked success cases to reliable, production-ready solutions remains a significant challenge that companies underestimate
The evolution of GenAI in enterprise settings requires focusing on deterministic, consistently reliable solutions rather than being swayed by impressive but limited demonstrations.
2. A Great guide to understanding Deepseek R1
DeepSeek-R1, a groundbreaking open-weight language model, demonstrates exceptional reasoning capabilities through an innovative three-step training approach. The model uniquely combines large-scale reinforcement learning with specialized reasoning data generation, requiring minimal human-labeled data. What sets it apart is its ability to process complex problems by generating detailed thinking tokens and its novel training method that includes creating an interim reasoning model to generate high-quality training data.
The blog breaks down the technical architecture and training recipe, showing how DeepSeek-R1 achieves strong performance in both reasoning and general tasks, making it a significant advancement in AI development.
🔬 Research Corner
Our team has been diving deep into groundbreaking research papers, and two particularly caught our attention:
1. Active Inheritance: A Novel Approach to Fine-Tuning Language Models
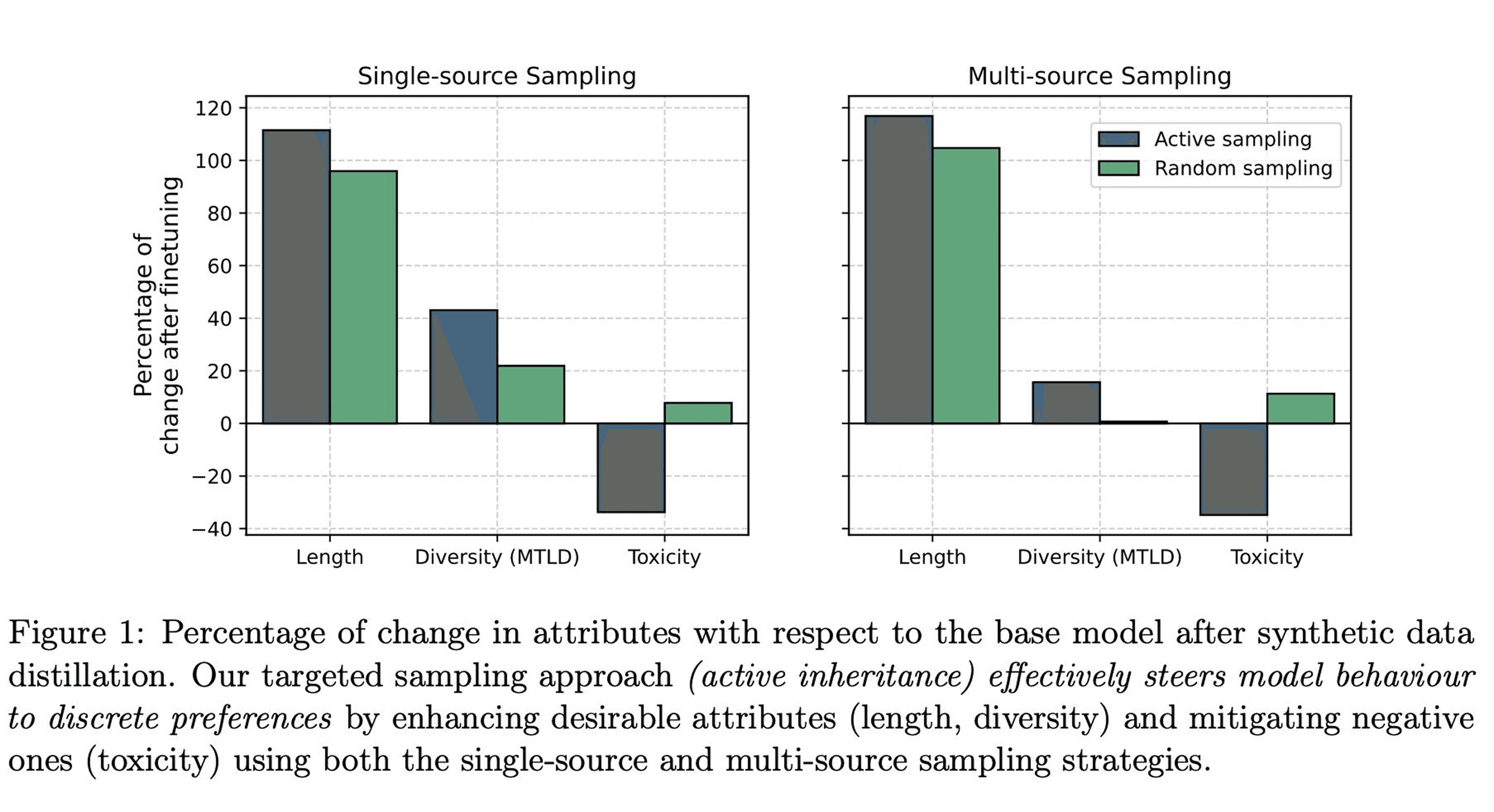
Researchers from Cohere have introduced a new method called Active Inheritance that improves fine-tuning of language models through selective synthetic data selection, offering better control over model behavior.
Key points:
Models trained on synthetic data inherently adopt properties from teacher models, including biases and response patterns, even with neutral prompts
The active Selection technique generates multiple responses per prompt and selects the best ones based on specific objectives (toxicity, calibration, lexical diversity), leading to more controlled fine-tuning
Significant improvements demonstrated: Mixtral 8x7B showed toxicity reduction from 65.2 to 43.2, while Llama 2 7B reduced from 71.7 to 50.7. Response length and lexical diversity improved by up to 116% and 43% respectively
This research is particularly significant as it demonstrates how careful selection of synthetic training data can effectively shape model characteristics, providing a more precise approach to fine-tuning large language models while reducing unwanted behaviors.
2. Question Answering over Patient Medical Records with Private Customized LLMs (This is Our Paper!)

This one is special! Our team released our own research at Genloop making medical records truly accessible to patients. Imagine being able to ask your Apple Watch questions about your health and getting answers based on your complete medical history. While our health data is already stored in FHIR format (Fast Healthcare Interoperability Resources) - the mandated framework for exchanging health records - most of us can't easily derive insights from this information. Whether it's your latest lab reports, vitals from your smartwatch, or hospital records, this valuable data often remains locked in complex, technical formats. We propose an approach that helps you get key health insights from your own data without compromising on privacy.
Key points:
Two-Stage Approach: We break the problem into two distinct parts: first identifying relevant FHIR resources, then generating accurate answers from them. Results - our models are 250x smaller than GPT-4 but achieve a 0.55% higher F1 score in resource identification and a 42% improvement in answer generation.
Privacy-First Architecture: Healthcare data demands the highest level of protection. Our solution uses edge deployment and private hosting to fully comply with healthcare privacy regulations (HIPAA, CCPA, BIPA) without compromising on performance.
Discovered Evaluation Biases: We found that GPT-4 displays a clear bias towards its own outputs. Interestingly, this "narcissistic bias" mainly emerges when the model knows explicitly it was evaluating its own response, not so much when model identities are hidden.
We are Hiring!
Our small team is expanding, and we are hiring a super talented Sr. Applied AI Researcher. If you want to work with an extremely talented team solving impactful problems in the LLM customization space or know someone who would be a great fit - please reach out to us on founder@genloop.ai. We are happy to share a referral bonus!
Looking Forward
The new characters in the AI space have changed the game completely and it would only be exciting moving forward. Thank you for reading! Share your thoughts with us, and don't forget to subscribe to stay updated on the latest in LLM customization.



