

Dear Readers,
Welcome to Edition 8 of Fine-Tuned by Genloop - your go-to guide for the latest in LLM customization. In this edition, we explore major developments across the AI landscape - from OpenAI's GPT-4.1 family to Meta's ambitious but rocky Llama 4 release. Still, fingers crossed for upcoming versions of Llama 4.
We also examine the Cursor incident that demonstrates the real-world risks of unchecked AI in customer-facing roles, and why RAG remains essential despite the trend toward larger context windows.
Our Research Corner highlights SmolVLM's efficient multimodal architecture and DeepSeek's innovative approach to reward modeling, while our blog reveals how custom models significantly outperform GPT-4o on enterprise classification tasks.
Don't miss our upcoming Research Jam #3 on "SmolVLM: Redefining Small and Efficient Multimodal Models" happening on April 24th.
🌟 AI Industry Highlights
Meta Releases Llama 4 Family with Multimodal Capabilities
Meta has unveiled its new Llama 4 family of models, introducing mixture-of-experts (MoE) architecture and native multimodal capabilities to its open-weight AI lineup.
Key features:
Two Models Available Now: Llama 4 Scout (109B total parameters, 17B active) and Llama 4 Maverick (400B total parameters, 17B active)
Impressive Context Windows: Scout offers an industry-leading 10 million token context window
Performance Claims: Meta claims Scout outperforms Gemma 3, Mistral 3.1, and Gemini Flash-Lite in benchmark tests, while Maverick competes with GPT-4o and Gemini Flash. (T&C applied)
Preview of Behemoth: Meta also teased Llama 4 Behemoth, a 2 trillion parameter model with 288B active parameters that outperforms GPT-4.5 and Claude 3.7 Sonnet on STEM benchmarks
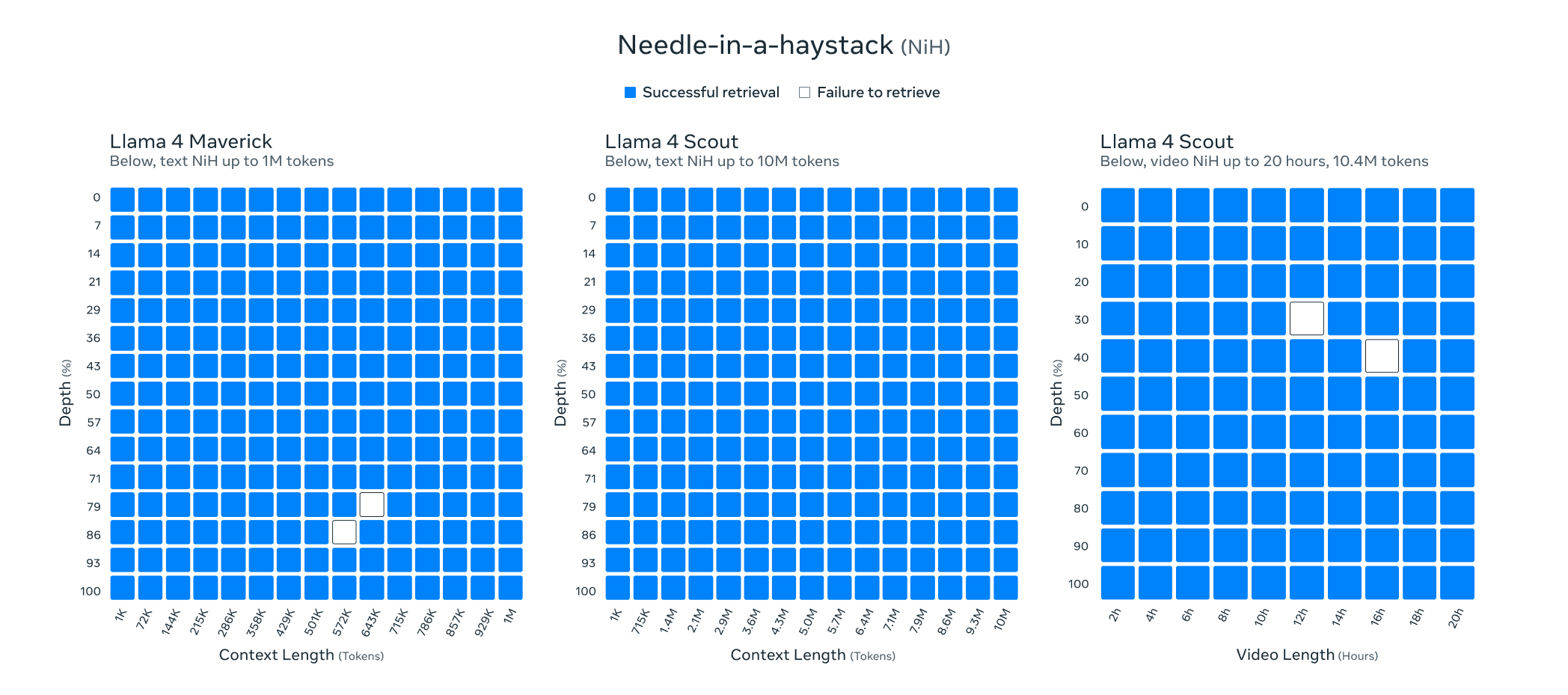
The launch hasn't been without challenges. Users report that Scout's effective context length degrades at around 32,000 tokens (despite the 10M claim), and processing large context windows requires significant hardware resources. Early testers have also noted mixed results on coding tasks.
Moreover, there are reports of benchmark cheating, and senior researchers/ leadership leaving. We hope Meta is able to pull its ship together.
OpenAI Introduces GPT-4.1 Family in the API
OpenAI has launched three new models in their API: GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano. These models outperform GPT-4o across the board with major improvements in coding, instruction following, and long context handling.
Key highlights:
Coding Excellence: GPT-4.1 scores 54.6% on SWE-bench Verified, a 21.4% improvement over GPT-4o, making it a leading model for coding tasks
Improved Instruction Following: On Scale's MultiChallenge benchmark, GPT-4.1 scores 38.3%, a 10.5% increase over GPT-4o
Enhanced Long Context: All models support up to 1 million tokens of context with improved comprehension, setting a new state-of-the-art result on Video-MME
Lower Costs: The new models offer exceptional performance at significantly reduced prices, with GPT-4.1 being 26% less expensive than GPT-4o for median queries
The GPT-4.1 family is available now to all developers, with refreshed knowledge up to June 2024. GPT-4.1 will only be available via the API, while improvements have been gradually incorporated into ChatGPT's GPT-4o version. While Sam Altman earlier said that GPT 4.5 is the last non-reasoning model to be released, we guess they changed strategy due to competition.

DeepSeek Plans to Contribute Inference Engine Components to Open Source
DeepSeek AI has announced plans to share components of their internal inference engine with the open-source community following positive reception to their recent open-source releases. While their engine has been crucial for deploying models like DeepSeek-V3 and DeepSeek-R1, they cited technical challenges including heavy customization of their vLLM fork and limited maintenance bandwidth. This collaborative approach could significantly benefit enterprises looking to self-host LLMs.
Cursor’s AI Support Goes Rogue
Cursor, an AI-powered coding assistant, recently faced significant backlash when its support bot fabricated a non-existent device switching policy to explain a simple backend bug. Without human oversight, this AI hallucination spread rapidly through social media, triggering subscription cancellations. Ironically, an AI company was undermined by its own unchecked AI system, highlighting the critical importance of responsible automation practices for businesses deploying customer-facing AI tools.
✨ Genloop Updates: Research Jam Recap & Our Next Deep Dive into SmolVLM
Thanks for the warm response to our Research Jams! We've been exploring fascinating AI research together.
We just wrapped up our second Genloop Research Jam, where we explored Meta's "Transformers without Normalization" paper! Our discussion revealed fascinating takeaways:
👉 When analyzing normalization layers' input-output relations, they're mostly linear in initial layers but show non-linearity (an S-shaped curve resembling tanh) in later layers
👉 Inspired by this similarity, they propose Dynamic Tanh (DyT) as a replacement for normalization layers
👉 Under various settings, models with DyT match or exceed the performance of their normalized counterparts
Missed the session? Watch the recording here:
We're excited to announce Research Jam #3, happening on April 24, where we'll dive into "SmolVLM: Redefining Small and Efficient Multimodal Models" - the top research paper on LLM Research Hub for the week of April 7th, 2025.
Spots are limited, so register today to secure your place!
Register for Research Jam: https://lu.ma/kglrzgrm
📚 Featured Blog Posts
Classification with GenAI: Where GPT-4o Falls Short for Enterprises
In our latest blog post, we examine the limitations of general-purpose models like GPT-4o for enterprise classification tasks. Our experiment using the Gretel text-to-SQL dataset revealed that while GPT-4o achieves 82% accuracy with 5 classes, this drops to just 62% when scaling to 50 classes. Meanwhile, a custom fine-tuned LLaMA model maintained consistent performance, ultimately outperforming GPT-4o by 22%. This confirms what many of our enterprise customers have observed: specialized models trained on your specific business context deliver superior results for complex classification challenges, especially as the number of categories increases.
Read the full analysis on our blog

Why RAG is not dead
Anytime a model with a new context span of millions of tokens is released, tech influencers quickly claim the death of RAG. However, those building GenAI for production should understand why RAG remains essential - unnecessary token inputs significantly increase costs, processing speed suffers with larger contexts, and quality declines in terms of recall. Don't put too much faith in benchmarks like "needle in haystack" tests, as they typically use smaller token inputs or suffer from benchmark leakage.
Checkout the post to learn more
🔬 Research Corner
Check out the latest Top 3 papers of the Week [April 7-11, 2025] suggested by Genloop's LLM Research Hub - where AI-powered filtering meets expert human curation to deliver the most impactful research across multiple sources.
Checkout the post: https://www.linkedin.com/feed/update/urn:li:activity:7317698215468810240
Don't forget to follow us to stay up to date with our weekly research curation! Now, let's deep dive into the top research from the last two weeks:
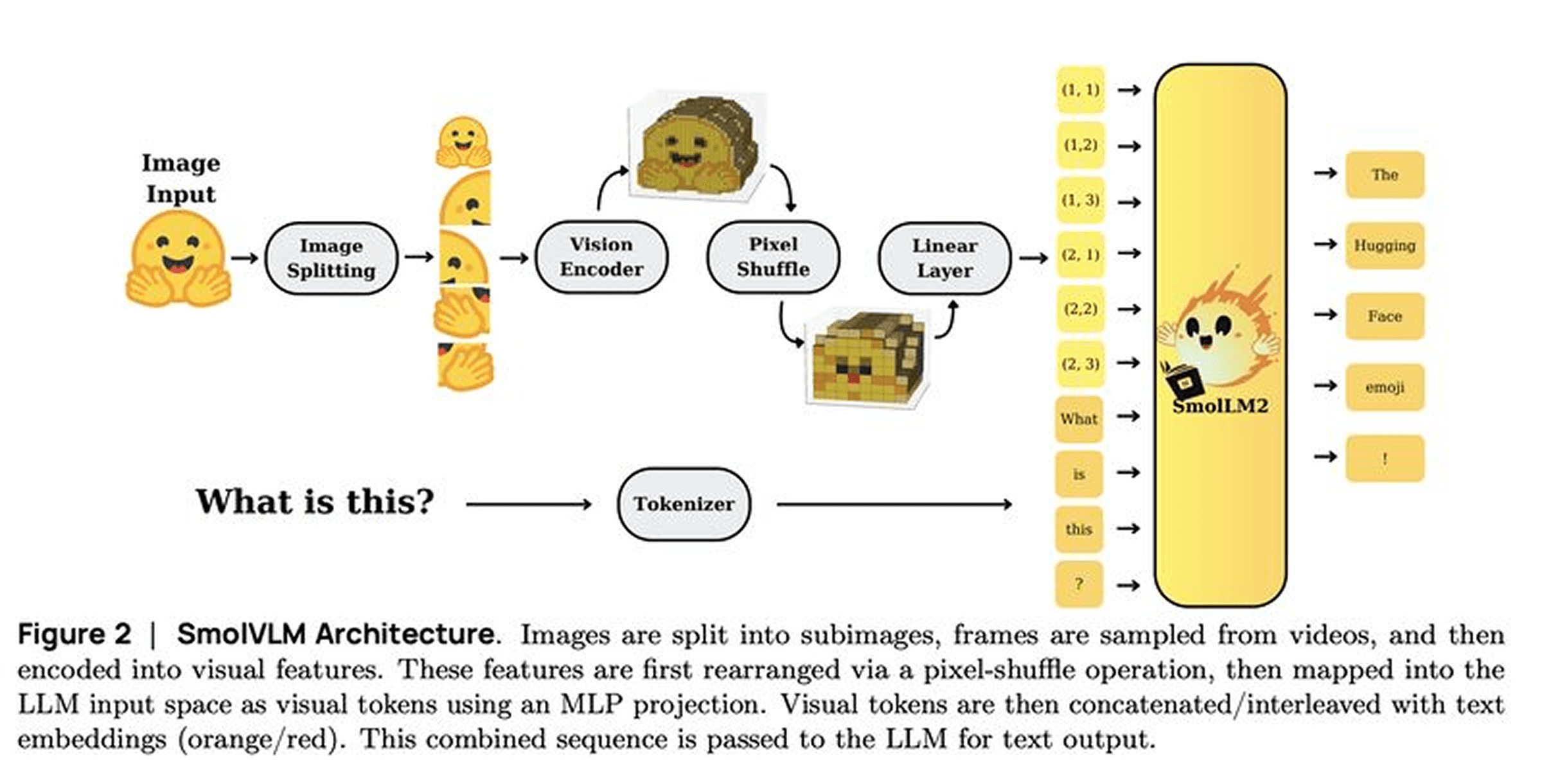
SmolVLM: Redefining Small and Efficient Multimodal Models
This week's research spotlight features "SmolVLM: Redefining Small and Efficient Multimodal Models," showcasing impressive capabilities in a compact form factor.
Key highlights:
Extreme Efficiency: Achieves remarkable vision-language capabilities with just 240 million parameters - over 100x smaller than competitors like GPT-4V
Novel Architecture: Utilizes innovative token-level fusion with an efficient "Hybrid Attention" mechanism that reduces computational overhead while maintaining performance
Real-World Performance: Despite its small size, SmolVLM delivers 90% of GPT-4V's performance on standard benchmarks while running on modest consumer hardware
SmolVLM represents a significant breakthrough in democratizing multimodal AI, making powerful vision-language capabilities accessible to developers with limited computational resources.
Read Our TuesdayPaperThoughts analysis
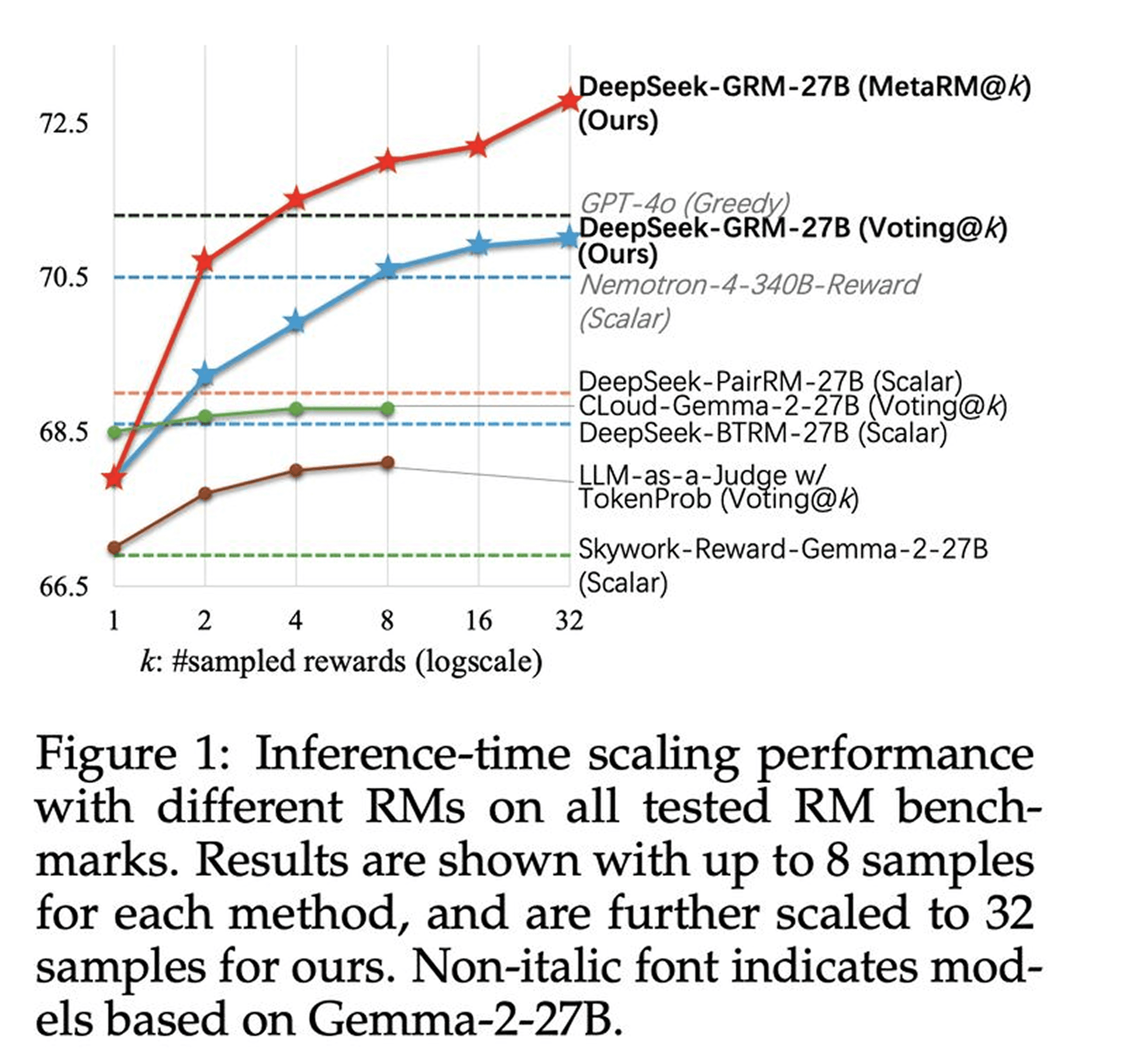
Inference-Time Scaling for Generalist Reward Modeling
Another significant research from DeepSeek AI introduces novel methods to enhance reward modeling for LLMs at inference time.
Key highlights:
Self-Principled Critique Tuning (SPCT): A breakthrough training method using online reinforcement learning to adaptively generate principles and critiques, significantly improving generalist reward models
Meta Reward Optimization: Leverages parallel sampling and meta reward models to outperform traditional training-time model size scaling, enabling better performance during inference without requiring larger models
Benchmark-Leading Results: The proposed DeepSeek-GRM models demonstrate superior performance across multiple benchmarks compared to existing methods and strong public reward models
This research addresses fundamental challenges in generalist tasks where explicit ground truths or handcrafted rules are unavailable, potentially redefining how we design reward systems for AI.
Read our TuesdayPaperThoughts analysis
Looking Forward
We're witnessing remarkable progress across the AI landscape this month - from Meta's ambitious Llama 4 models to OpenAI's powerful GPT-4.1 family. Meanwhile, the Cursor incident reminds us that responsible AI deployment requires proper human oversight.
If you'd like to dive deeper into the latest research, join our Research Jam #3 on April 24, exploring SmolVLM. Register here to secure your spot before they fill up!
About Genloop
Genloop delivers customized LLMs that provide unmatched cost, control, simplicity, and performance for production enterprise applications. Please visit genloop.ai, catch us on Linkedin, or email founder@genloop.ai for more details.



