

2024 was a landmark year for Large Language Models (LLMs).
While GPT-4 set the standard early on, open-source innovation surged ahead, closing the performance gap at an unprecedented pace. By the end of the year, open-source models reached performance levels on par with GPT-4.
This shift opened exciting new opportunities for enterprises. Fine-tuning open-source models now allows businesses to build specialized AI solutions that are more precise, cost-effective, and tailored to their unique needs. In fact, 76% of companies that use LLMs are choosing open-source models, often alongside proprietary models.
Genloop's journey began at the heart of this evolution.
Starting mid-2024, we partnered with top enterprises to harness the power of LLM customization, solving complex challenges and driving meaningful R&D impact. As we move into 2025, we believe more strongly than ever in the value of customized LLMs.
Thank you for joining us on this journey. Here’s to a year of growth and innovation in 2025!
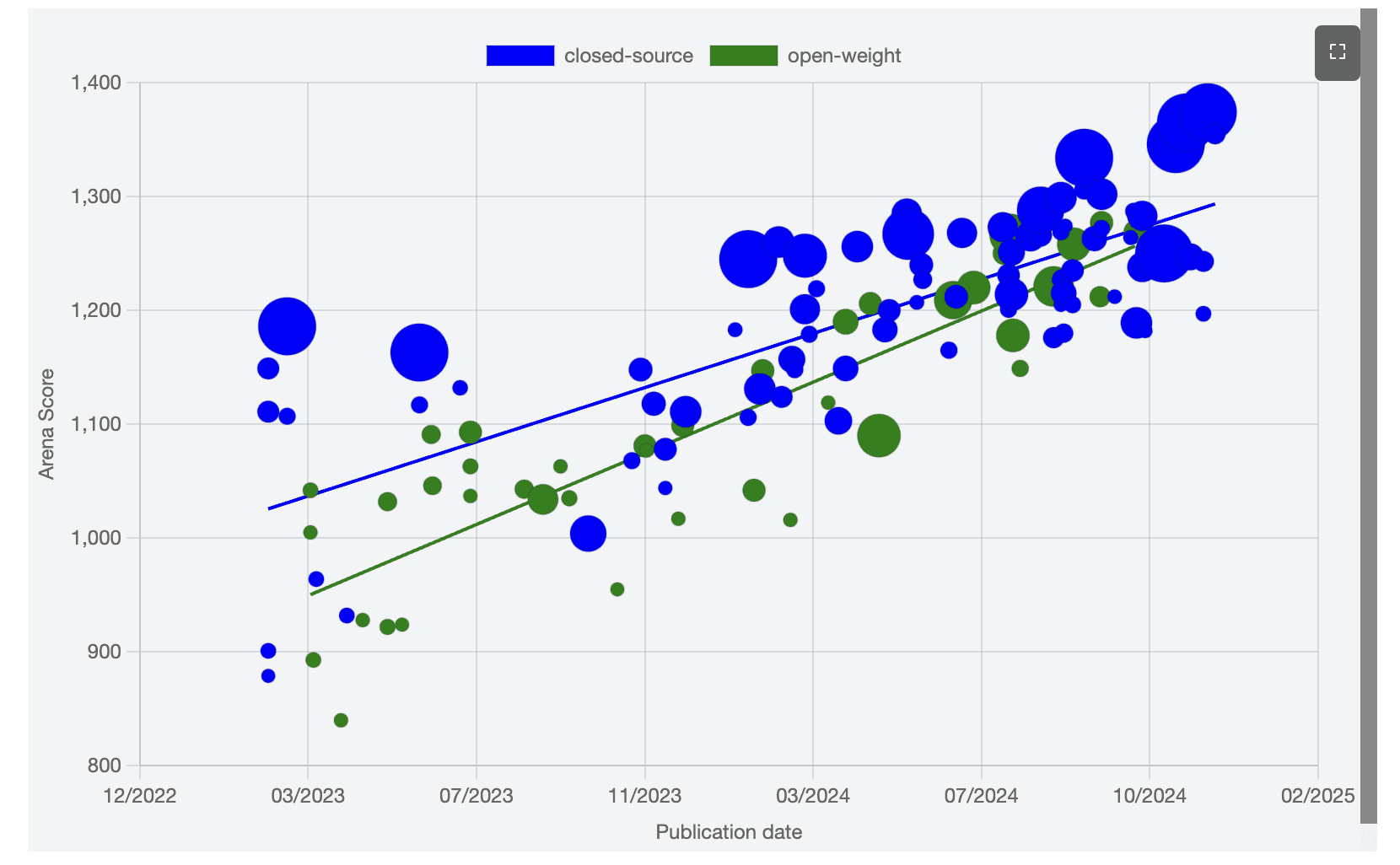
Performance Gap between Closed-Weight and Open-Source Models Closed from years to months in 2024. Source: https://huggingface.co/spaces/huggingface/open-source-ai-year-in-review-2024?day=19
The Rise of Small Language Models (SLMs)
A significant trend in 2024 was the growing prominence of Small Language Models. The industry moved away from the "bigger is better" mentality. Llama 3 8B demonstrated superior performance compared to Llama 2 70B, while Llama 3.3's 70B model matched the capabilities of Llama 3.1's 405B model. Microsoft’s Phi series, Meta’s Llama 3.2, Google’s Gemma series, Qwen’s 2.5 series, and Hugging Face Smol models lead the space. Model compression techniques like distillation, quantization, and pruning were primarily used to build these smaller models. SLMs are the primary reason we saw a significant price drop in LLM usage over the year.
2024 also made running LLMs on local compute possible. Llama.cpp, Ollama, Open WebUI, and GGUF emerged as best solutions to interacting with LLMs locally. It re-imagined how we interact with AI technology, giving immense control and freedom to the end users.
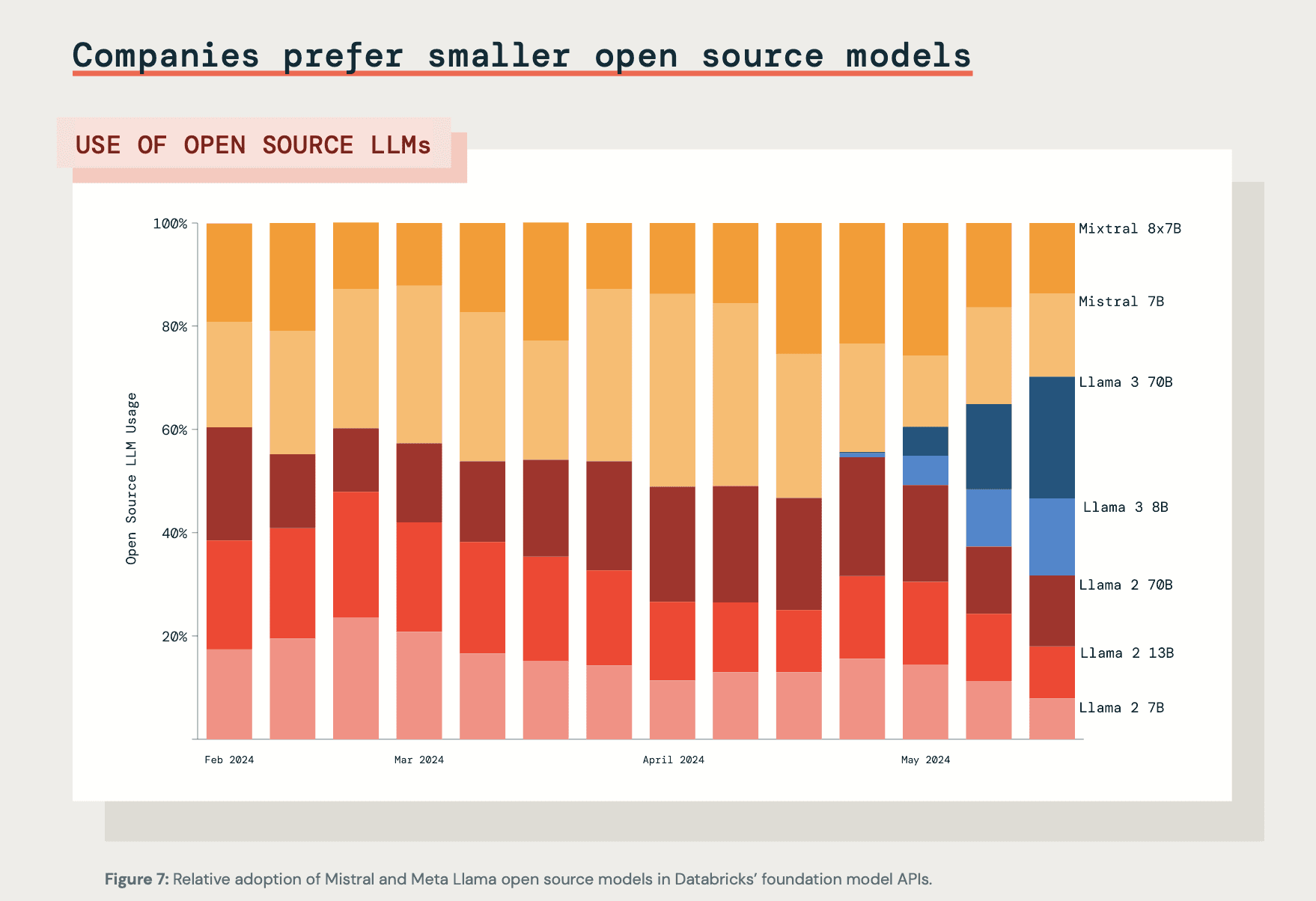
Source: Databricks State of Data + AI Report (https://www.databricks.com/resources/ebook/state-of-data-ai)
Enterprise Adoption and Implementation
The surge in enterprise AI spending shows growing corporate commitment to AI technology, but adoption remained largely experimental. Investment skyrocketed to $13.8 billion, up from 2023's $2.3 billion figure.
Enterprise decision-making on adopting GenAI tools or applications revealed clear priorities:
Return on investment emerged as the primary consideration, accounting for 30% of selection criteria
Industry-specific customization followed closely at 26%
However, implementation wasn't without its challenges. Organizations encountered several key obstacles:
Implementation costs derailed 26% of pilot projects
Data privacy concerns impacted 21% of initiatives
Disappointing ROI affected 18% of deployments
Technical issues, particularly hallucinations, disrupted 15% of projects
Selecting use cases with positive ROI, educating oneself about Generative AI, becoming data-ready, and neither fearing nor hyping GenAI will lead to successful enterprise outcomes in 2025.
40% of GenAI spending now comes from permanent budgets, with 58% redirected from existing allocations, suggests growing organizational commitment to AI transformation. However, over a third of surveyed organizations lack a clear vision for GenAI implementation indicates we're still in the early stages of this technological revolution.
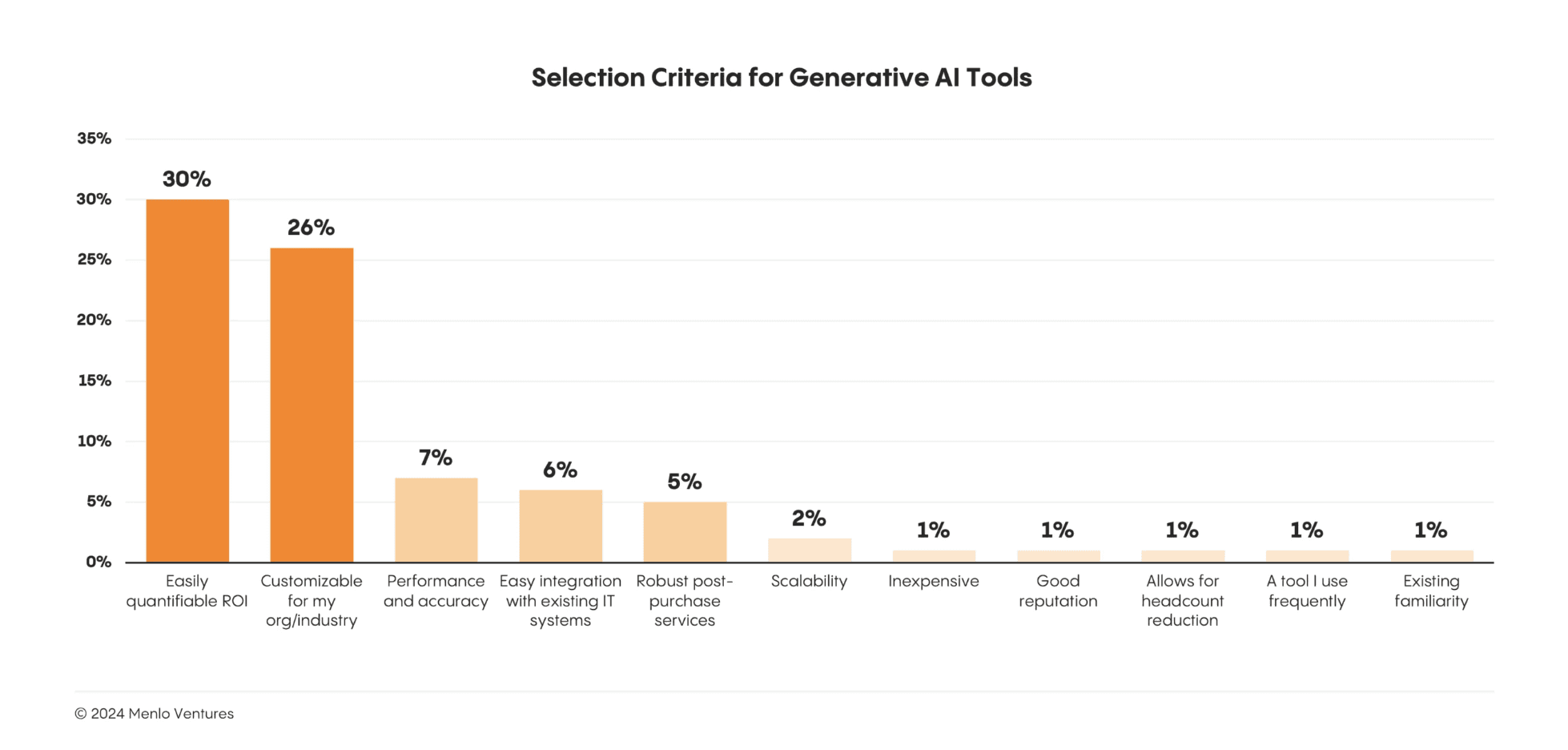
ROI and Customizability are most important selection criteria for GenAI Tools. Source: The State of Generative AI in the Enterprise (https://menlovc.com/2024-the-state-of-generative-ai-in-the-enterprise/)
Multi-Model and Multi-Modal Strategies
Enterprises started adopting multi-model approaches, with studies showing organizations using at least three distinct foundational models in their stack. OpenAI was the biggest loser, and Anthropic the biggest winner in capturing the market share. This indicates growing maturity of the stack, and applications moving towards robustness.
Multi-Modality also became a strong focal point. Multi-Modal LLMs are capable of processing multiple types of inputs, such as text, sound, images, and videos all at once. OpenAI, Anthropic, Google, Meta, and Qwen - all released their multi-modal LLMs that have unlocked various use cases.
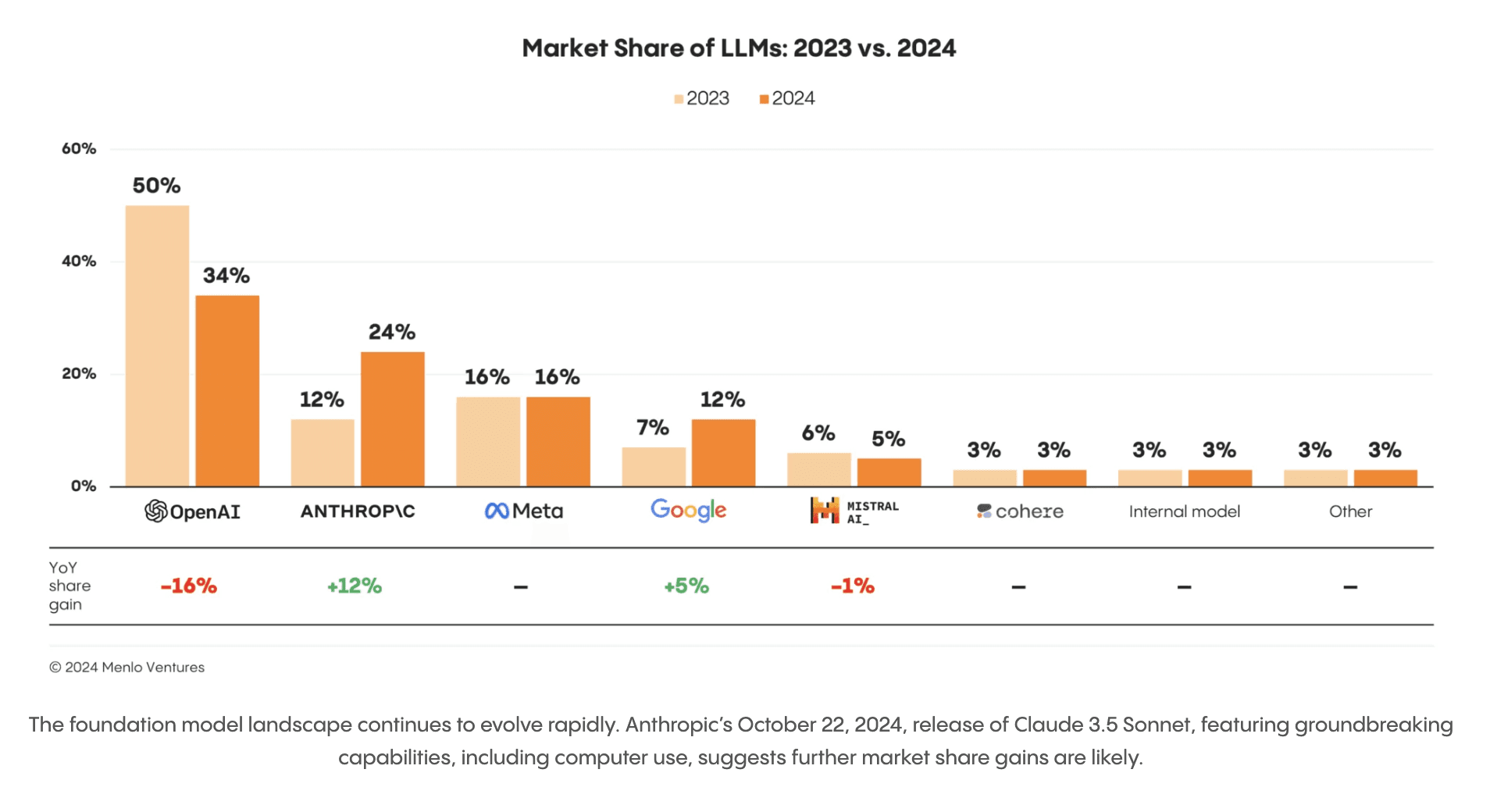
OpenAI cedes market to Anthropic as Enterprise AI Stacks progress towards robust performance. Source: The State of Generative AI in the Enterprise (https://menlovc.com/2024-the-state-of-generative-ai-in-the-enterprise/)
Major Releases and Industry Milestones
Let’s go over the significant turnpoints in the year for LLMs and their customization efforts. This timeline showcases the rapid pace of innovation and the industry's shift toward more efficient, specialized, and accessible AI models throughout 2024.

Timeline of Major Releases and Industry Milestones in 2024
Q1: Foundation Setting
January
GPT-4 maintained its position as the leading closed-source model
The New York Times filed a landmark lawsuit against OpenAI and Microsoft over copyright infringement, challenging the fundamental training practices of AI models
The suit sparked industry-wide discussions about fair use and training data rights, remaining unresolved through year's end
February
OpenAI unveiled Sora, introducing sophisticated text-to-video generation capabilities. It was released to the public in December though.
Google released Gemini 1.5 Pro, revolutionizing context handling with its 1-million token context window
Google also launched Gemma, their lightweight open model family, derived from Gemini technology
The Gemma models (2B and 7B variants) accumulated millions of downloads within months
March
Microsoft released the Phi-3 family, introducing Phi-3-mini (3.8B parameters)
Anthropic launched the Claude 3 series (Haiku, Sonnet, and Opus)
Claude Opus emerged as the strongest competitor to GPT-4
Q2: Evolution and Efficiency
April
Intel introduced the Gaudi 3 GPU, aiming to compete with Nvidia's H100
Meta released the Llama 3 series, marking a significant advancement in open-source models
Leadership challenges at Intel impacted market confidence in their AI chip strategy
May
OpenAI launched GPT-4o, optimized for multimodal applications with improved speed and reduced costs
Google enhanced its Gemma lineup with 1.5 Pro and 1.5 Flash variants
The Flash variant specifically targeted high-frequency tasks requiring rapid response times
June
Google released Gemma 2 with 27B and 9B parameter models
The 27B variant achieved top rankings on the LMSYS Chatbot Arena leaderboard
Anthropic introduced the Claude 3.5 series, featuring the Claude 3.5 Sonnet as their most intelligent model
Q3: Innovation Acceleration
July
Mistral AI released NeMo, demonstrating strong performance metrics
OpenAI introduced GPT-4O mini, offering a more cost-effective solution
Meta launched Llama 3.1, including the groundbreaking 405B parameter model
Hugging Face released SmolLM series (135M, 360M, and 1.7B parameters)
August
The EU AI Act implementation began, setting new regulatory standards
OpenAI announced significant price reductions: 50% for input tokens and 33% for output tokens
September
Meta released the Llama 3.2 series, featuring improved multimodal capabilities
OpenAI introduced the O1 series focused on reasoning and decision-making
Alibaba launched the Qwen 2.5 series, expanding its model lineup
Q4: Year-End Breakthroughs
October
Anthropic released major updates to Claude's capabilities
Claude gained computer interaction abilities, marking a significant advancement in AI-system interaction
The updates included improved Claude 3.5 Sonnet and new Claude 3.5 Haiku variants
November
Qwen released QwQ, their response to OpenAI's O1 series
The industry saw an increased focus on specialized reasoning models
December
Google topped GenAI benchmarks with Gemini Flash 2.0 Experimental
OpenAI released the O3 model and Sora Turbo
Google releases Veo2. Veo2 demonstrated superior performance compared to Sora
Meta launched Llama 3.3, achieving similar performance to 3.1 405B with just 70B parameters
NVIDIA released the $250 Jetson Orin Nano Supercomputer for local AI processing
DeepSeek v3 launched with 671B parameters, outperforming GPT4O on some benchmarks
Best LLM Research Papers of 2024
Arxiv kept buzzing with interesting research papers throughout the year, never leaving an AI enthusiast unoccupied. But here are our top 3 paper-read recommendations for 2024
Llama 3 Herd of Models: Goes in detail about data preparation, training, and investigating scaling laws. This is a landmine of information for all LLM tinkerers.
DeepSeek-v3 Technical Report: Goes into impressive details on training with the cheapest compute, and trying newer approaches like Multi-Head Latent Attention (MLA) and mutli-token prediction objective. DeepSeek-V3's entire training process costs only $5.576M (2.788M H800 GPU hours), yet achieves performance competitively with leading closed-source models. This is the best open-weight model right now, so definitely worth the read.
Byte Latent Transformer: Ending 2024 was one of the most promising architectural developments for 2025 - a new byte-level LLM architecture from meta that matches tokenization based LLM performance at scale. Cannot miss it!
Looking Ahead: The Promise of 2025
The industry stands at a fascinating crossroads. Data quality improvements and scaling have outpaced compute scaling in delivering enhanced performance. This suggests that future advances will likely come from smarter training approaches rather than brute-force computation. This is in-line with Ilya Sutskevar’s viral talk at Neurips 2024 AI conference in Dec ‘24. Sutskevar suggests “Pre-training (training a large model) as we know it will unquestionably end” because “we have but one internet”.
As we move into 2025, the focus will likely shift from raw model size to efficiency and practical application. The success of smaller, more specialized models has demonstrated that targeted solutions often outperform general-purpose behemoths. This trend, combined with the rapid advancement of open-source capabilities, suggests a 2025 where AI becomes more accessible, efficient, and precisely tailored to specific use cases
Key areas to watch in 2025 include:
Further developments in inference time scaling and their open-source implementations
Evolution of reasoning capabilities in Small Language Models
New fine-tuning approaches like RFT and their open-source implementations
Increased focus on production-grade GenAI implementations
Enhanced control and performance optimization in enterprise deployments
About Genloop
Genloop delivers customized LLMs that provide unmatched cost, control, simplicity, and performance for production enterprise applications. Please visit genloop.ai or email founder@genloop.ai for more details.



