

In the rapidly evolving landscape of artificial intelligence, Large Language Models (LLMs) have become transformative tools for enterprise innovation. While these models offer remarkable capabilities out of the box, many organizations are discovering that fine-tuning - the process of customizing models for specific use cases - can dramatically improve their effectiveness. This guide explores Why, When, and How to fine-tune LLMs for optimal results.
Understanding the LLM Landscape
Today's enterprises have three primary approaches to implementing generative AI:
General-Purpose Closed Models: Services like GPT-4, Claude, and Gemini offer powerful, pre-trained models through APIs. These models excel at general tasks but come with usage costs and privacy considerations.
Open-Source Models: Companies like Meta and Mistral provide models that can be self-hosted or accessed through providers like Together AI. While typically more cost-effective, these models often trail their closed-source counterparts in general performance.
Fine-Tuned Open Source Models: This hybrid approach involves customizing open-source models for specific applications. Think of it as training a specialist rather than relying on a generalist - you get higher accuracy for your specific needs without paying for unnecessary capabilities.

The Foundation: Understanding How LLMs Learn
Imagine teaching a highly capable student who can adapt their knowledge to new situations. LLMs learn in similar ways, through three primary mechanisms:
Prompt Engineering: Like giving clear instructions to a student, this involves crafting specific inputs to guide the model's responses. For example, when teaching a model to analyze customer feedback, you might provide explicit instructions about tone, format, and key points to consider.
Fine-Tuning: Similar to focused practice sessions, this process helps the model excel at specific tasks through repeated exposure to relevant examples. A model fine-tuned for medical diagnosis, for instance, would learn to recognize subtle patterns in patient descriptions.
Pre-Training: This fundamental learning phase is comparable to basic education, where the model learns language patterns and general knowledge from vast amounts of data.

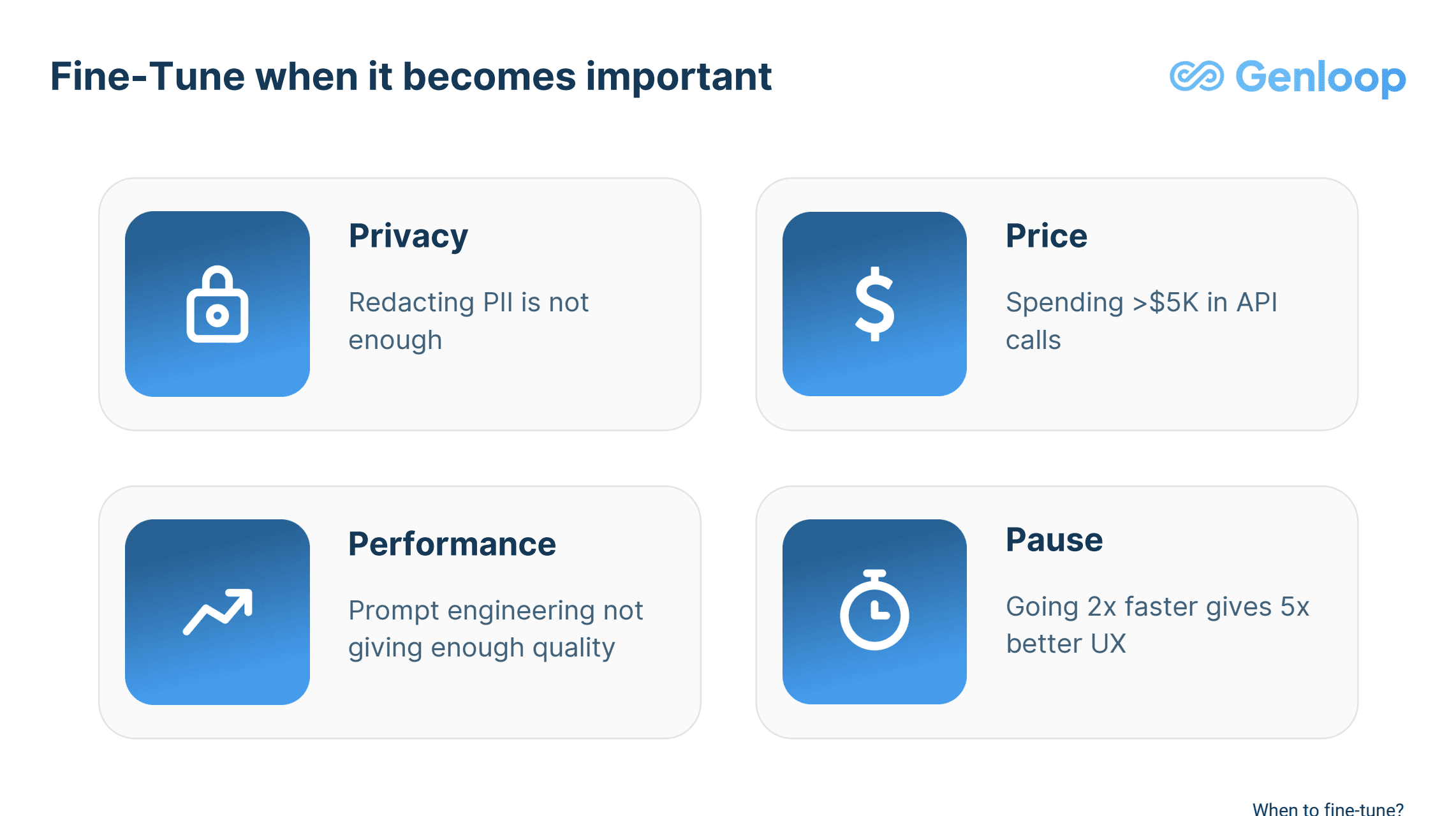
The 4P Framework: Evaluating Why to Fine-tune
Before diving into fine-tuning, organizations should evaluate their needs through the lens of four critical factors:

Performance
Fine-tuning becomes essential when:
Standard models consistently miss nuances specific to your industry
You need to maintain context across complex, multi-turn interactions
Your use case requires handling edge cases with high accuracy
You want the model to learn from user feedback and improve over time
You want the model to run on low compute
Price
Consider the real-world cost implications: A detailed example: An automotive company processing customer service calls
Each transcript: 50,000 tokens input + 500 tokens output
Cost per call with GPT4o API: 50,000 * $0.0025/1000) + (500 * $0.01/1000) = $0.13
At 100,000 calls monthly: $130,000
Annual API costs: $1.5M
Fine-tuning a smaller, specialized model could reduce these costs significantly while maintaining or improving performance.
Pause (Speed)
Speed becomes critical when:
Your application requires real-time responses (like customer service chatbots)
You're processing large volumes of data with tight timeframes
User experience depends on quick response times
You need to optimize resource utilization in your infrastructure
Privacy
Security considerations include:
Protection of sensitive enterprise data
Compliance with industry regulations
Safeguarding intellectual property
Managing risk in regulated industries
When Should You Fine-tune Your LLM? A Practical Decision Guide
Making the decision to fine-tune an LLM requires careful evaluation of multiple factors. Let's explore each decision criterion in depth to help you make an informed choice for your organization.
Privacy Requirements
When handling sensitive data, fine-tuning becomes essential rather than optional. Consider fine-tuning when your organization:
Processes data that includes personally identifiable information, such as healthcare records or financial transactions. For instance, a healthcare provider analyzing patient records would need complete control over how their data is processed and stored.
Works with intellectual property or trade secrets. Manufacturing companies developing new products often need to process technical documentation and specifications that contain proprietary information.
Operates in regulated industries where data governance is crucial. Financial institutions handling transaction data or legal firms processing case information must maintain strict control over their data processing pipeline.
Must comply with specific regional regulations like GDPR or HIPAA. Organizations operating in the EU, for example, need to ensure their AI systems meet data residency requirements.
Cost Analysis Framework
The $5,000 monthly API cost threshold serves as a practical starting point for considering fine-tuning, but the full cost analysis should include:
Base API Costs:
Calculate your current token usage (input + output tokens)
Project growth in usage over the next 12-24 months
Factor in potential API price changes
Infrastructure Costs:
Computing resources for model hosting
Storage requirements for training data
Monitoring and maintenance systems
Development and operations team costs
Long-term ROI Calculation:
For example, if your monthly API costs are $10,000 and your initial fine-tuning investment was $20,000 to set up with $2,000 monthly maintenance, your break-even period would be:
Accuracy Requirements
Fine-tuning becomes necessary when standard models consistently fall short of required accuracy levels. Consider these specific scenarios:
Task-Specific Performance Gaps:
Current model accuracy falls below 85% for your specific use case
Critical errors occur in more than 2% of responses
Edge cases are handled incorrectly more than 5% of the time
Your engineering is becoming complex to steer the General LLMs
Industry-Specific Requirements:
Legal document analysis requiring over 95% accuracy
Medical diagnosis support needing 99%+ accuracy
Financial compliance checks demanding near-perfect accuracy
Performance Tracking Framework:
Establish baseline performance metrics using standard models
Document specific failure cases and their frequency
Calculate the business impact of accuracy improvements
Set clear accuracy targets for the fine-tuned model
Speed Requirements
Latency becomes a critical factor in these scenarios:
Real-time Applications:
Customer service chatbots requiring responses in under 5 sec
Trading systems needing analysis in milliseconds
Live translation services with strict timing requirements
Data Processing Constraints:
Daily data processing pipelines with fixed time windows
Regular report generation with strict deadlines
High-volume document analysis with throughput requirements
Speed Evaluation Matrix:
Objective Evaluation Framework
To make a final decision, score your use case against these criteria. You can also try this LLM Fine-Tuning Evaluator to determine if you need to fine-tune your LLM.Privacy Score (0-10):
Privacy Score (0-10):
0: No sensitive data
5: Some confidential business data
10: Highly regulated, sensitive personal data
Cost Score (0-10):
0: < $1,000/month API costs
5: $5,000-$15,000/month
10: > $30,000/month
Accuracy Score (0-10):
0: Current accuracy is acceptable
5: Notable accuracy gaps
10: Critical accuracy requirements unmet
Speed Score (0-10):
0: No strict latency requirements
5: Quick responses needed
10: Real-time processing required
Decision Matrix:

The LLM Development Lifecycle

Success in fine-tuning requires a systematic approach:
Strategic Planning
Define clear objectives and success metrics
Identify specific use cases and requirements
Set realistic performance targets
Data Preparation
Curate high-quality training data
Create diverse example sets
Develop a comprehensive golden dataset
Model Selection & Training
Choose appropriate base models
Evaluate models objectively without bias
Monitor and validate results
Deployment & Maintenance
Set up robust monitoring systems
Track model drift and performance
Implement feedback loops for continuous improvement
We’ll cover more details on the LLM Development cycle in another blog.
Looking Ahead: The Future of Custom AI
As AI technology continues to evolve, fine-tuning will become increasingly important for organizations seeking to maintain competitive advantages. The ability to create specialized, efficient models tailored to specific needs will likely become a core competency for successful enterprises.
For organizations beginning their fine-tuning journey, remember that success requires ongoing commitment to model improvement and maintenance. The initial investment in fine-tuning can lead to significant long-term benefits in performance, cost, and control over your AI capabilities.

About Genloop
Genloop is a team of experts from Stanford University, CMU, the IITs, and leading MAANG firms, specializing in developing enterprise-grade Generative AI solutions. We focus on creating customized Large Language Models tailored to the unique needs of each enterprise and automating their LLMOPs to improve efficiency. Essentially, we help convert the high dev effort attribute of fine-tuning open source models to green.



