
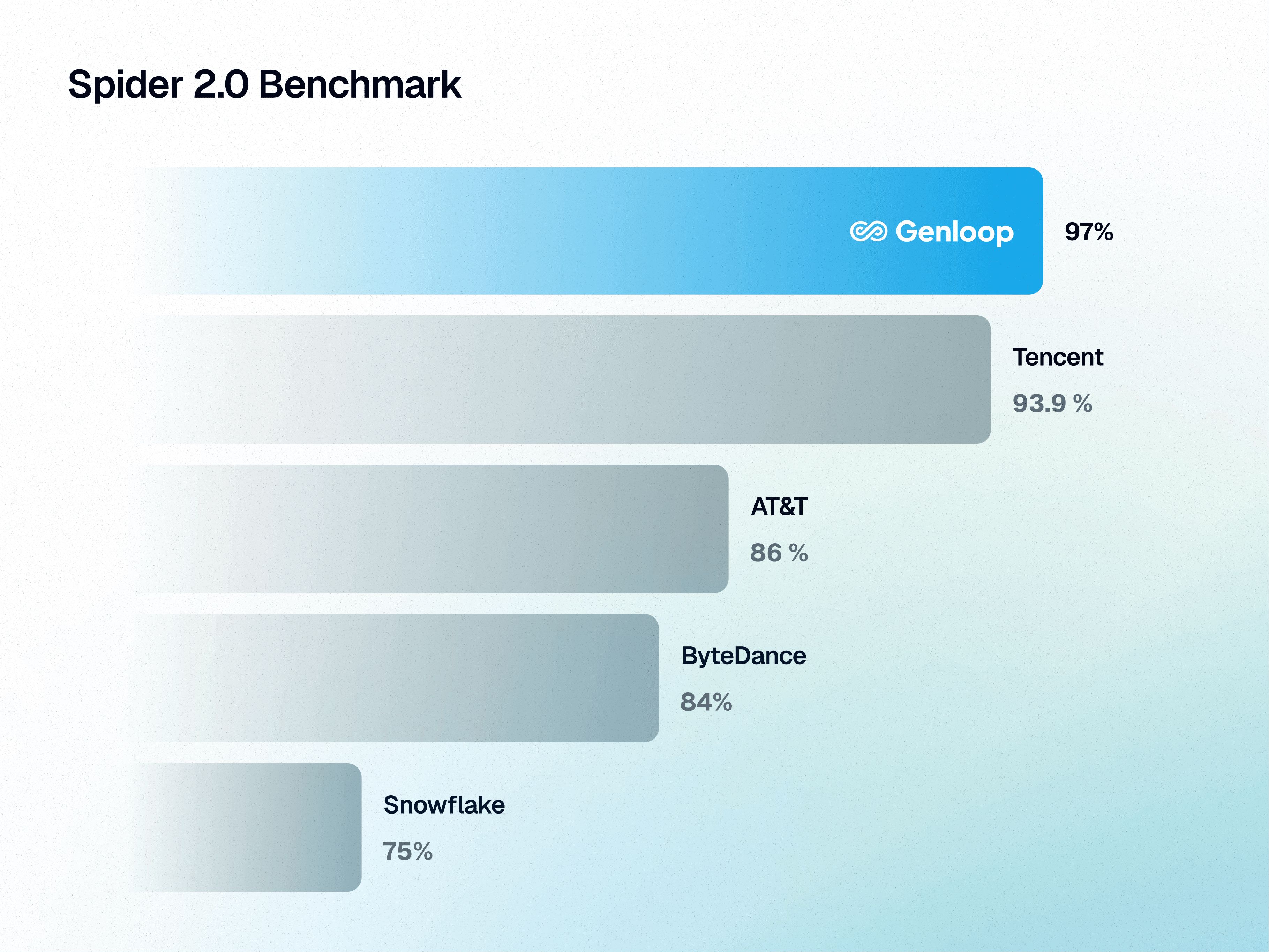
On March 1, 2026, Genloop's Sentinel Agent v2 Pro scored 96.70 on Spider 2.0-Snow, putting us at the top of the leaderboard, ahead of teams from Tencent, AT&T, ByteDance, Snowflake, and others.
For context on what that gap looks like:
Tencent: 93.9%
AT&T: 86%
ByteDance: 84%
Snowflake: 75%
What is Spider 2.0?
Spider 2.0 is one of the most challenging data reasoning benchmarks out there. And this isn't a toy setup.
It pushes systems to reason across 150+ real-world databases, 13,000+ tables, and 500,000+ columns. Messy metadata, inconsistent schemas, multi-step reasoning across siloed sources. The kind of data estate that actually exists inside enterprises, not clean academic datasets built to make systems look good.
The teams that attempt it aren't doing so for fun. ByteDance, Tencent, Snowflake, AT&T, research labs from across the world have all taken a run at it. Scoring well here is hard precisely because the benchmark doesn't forgive shortcuts.
Why we're able to do this
The short answer: we don't just translate questions into SQL. We build a context graph of your data environment, and we reason against that, not just against raw schema.
Genloop's platform maintains what we call Unified Business Memory, a governed layer that holds your business logic, metric definitions, join paths, and team-specific context. When Sentinel Agent processes a question, it's not guessing at what "revenue" means in your schema. It already knows, because we've encoded that understanding over time.
The deeper architecture behind this is covered in detail on our platform page. If you want to understand why most text-to-SQL systems plateau around 80-85% on real-world benchmarks and what it takes to push past that, that's a good place to start.
What this means if you're an enterprise
If your team is evaluating conversational analytics or text-to-SQL infrastructure, benchmarks like Spider 2 matter because they're the closest proxy to what actually breaks in production. Not the easy queries, every vendor handles those. The ones where your schema is inconsistent, your question is ambiguous, and the system has to reason its way to a correct answer anyway.
96.70% on Spider 2.0-Snow means we get there more often than anyone else on the leaderboard right now.
We're not stopping here. The next version of Sentinel is already in testing.
If you want to see how this performs on your data, reach out to us or explore what the platform does under the hood at genloop.ai.


Give Every Team the Analyst They've Been Waiting For


Santa Clara, California, United States 95051
© 2026 Genloop™. All Rights Reserved.