

Dear Readers,
Welcome to the 11th edition of Fine-Tuned by Genloop! This week we're exploring Anthropic Claude 4's enhanced coding capabilities and DeepSeek's improved R1-0528 model. We also cover a startling revelation about Builder.ai, where the $1.5 billion "AI" company collapsed after it was discovered that human developers in India were posing as AI bots.
We're delighted to share updates on our pharmaceutical collaboration with Axtria and insights from our latest Research Jam session.
Let’s dive in!
🌟 AI Industry Highlights
DeepSeek Releases Enhanced R1-0528 Model with Improved Reasoning
DeepSeek has launched an updated version of its reasoning model, R1-0528, leveraging increased compute and post-training algorithmic optimization. It shows significant improvements in mathematical and coding benchmarks while maintaining competitive performance against leading models.
Key highlights:
Major Performance Gains: AIME 2025 accuracy jumped from 70% to 87.5%, with the model now using 23K tokens per question compared to 12K in the previous version
Competitive Benchmarks: Performance now approaches O3 and Gemini 2.5 Pro across mathematics, programming, and general logic tasks
8B Distilled Version: Also released DeepSeek-R1-0528-Qwen3-8B, achieving state-of-the-art performance among open-source models on AIME 2024
The updated model features reduced hallucination rates, enhanced function calling support, and better coding experience, while maintaining the ability to run locally with just 4GB download requirements.

Claude 4 Sonnet and Opus Set New Coding Benchmarks
Anthropic launched Claude 4 Sonnet and Claude 4 Opus, featuring enhanced coding capabilities, optional reasoning modes, and parallel tool usage, while also making Claude Code generally available.
Key highlights:
Top Coding Performance: Both models tied with Google Gemini 2.5 Pro on LMSys WebDev Arena and achieved state-of-the-art results on SWE-bench Verified (72.5-72.7% success rate vs OpenAI o3's 70.3%)
Advanced Features: Support for parallel tool use, visible reasoning tokens, computer use capabilities, and file manipulation for extended memory storage
Pricing and Availability: Claude Sonnet 4 at $3/$15 per million tokens, Claude Opus 4 at $15/$75 per million tokens, available via Anthropic API, Amazon Bedrock, and Google Cloud

Builder.ai Collapses After Being Exposed as Human-Powered Operation
The $1.5 billion AI startup Builder.ai has filed for bankruptcy after revelations that its "AI-powered" platform was actually operated by human developers in India pretending to be bots.
Key highlights:
$450 Million Raised: The company secured funding from major investors including Microsoft, Qatar Investment Authority, World Bank's IFC, and SoftBank before the deception was exposed
Eight-Year Fraud: Former employees revealed the company had no actual AI technology, instead using Indian developers to manually write code while claiming it was AI-generated
Financial Collapse: Lender Viola Credit withdrew $37 million from company accounts, leaving only $5 million in restricted funds and forcing bankruptcy proceedings across five countries
The scandal has prompted regulatory scrutiny of AI marketing practices and serves as a cautionary tale about transparency in the AI startup ecosystem during the current hype cycle.
✨ Genloop Updates
Genloop X Axtria: Powering Agentic AI for Pharma
In the last edition we were thrilled to announce our partnership with Axtria to build GenAI for pharma space. Our founder Ayush Gupta recently shared why the space has so much scope to enable real automation.
Our collaboration focuses on creating AI agents that truly understand pharma's workflows and enable real automation with the accuracy, privacy, and personalized intelligence that the industry demands. Read our founder's full thoughts
We'll be sharing more valuable insights at Axtria's Ignite conference on June 4-5 in Princeton, NJ.

Research Jam #5: Training Retrievers for Reasoning Tasks
Last week's Research Jam #5 delivered another engaging session as we dove deep into the "ReasonIR - Training Retrievers for Reasoning Tasks" paper. Our team explored how this 8B parameter retriever achieves state-of-the-art performance in complex reasoning information retrieval through innovative query refinement techniques.
Key takeaways included the ReasonIR Synthesizer's novel data generation architecture for creating varied query datasets, and the nuanced impact of query refinement, which significantly boosts performance across most models but can actually decrease performance on specific benchmarks like GPQA. Watch the full recording here:
Join Research Jam #6: Qwen3 Technical Report Deep Dive
Research Jam #6 is happening on June 12, where we'll dive into Qwen3 Technical Report - the top research paper on LLM Research Hub for the week of May 19th, 2025.
Spots are limited, so register today to secure your place!

🔬 Research Corner
Check out our latest Top 3 Papers of the Week [May 26 - May 30, 2025]. Each week, our AI agents score the internet for the best research papers, evaluate their relevance, and our experts carefully curate the top selections. Don't forget to follow us to stay up to date with our weekly research curation!

Now, let's deep dive into the top research from the last two weeks:
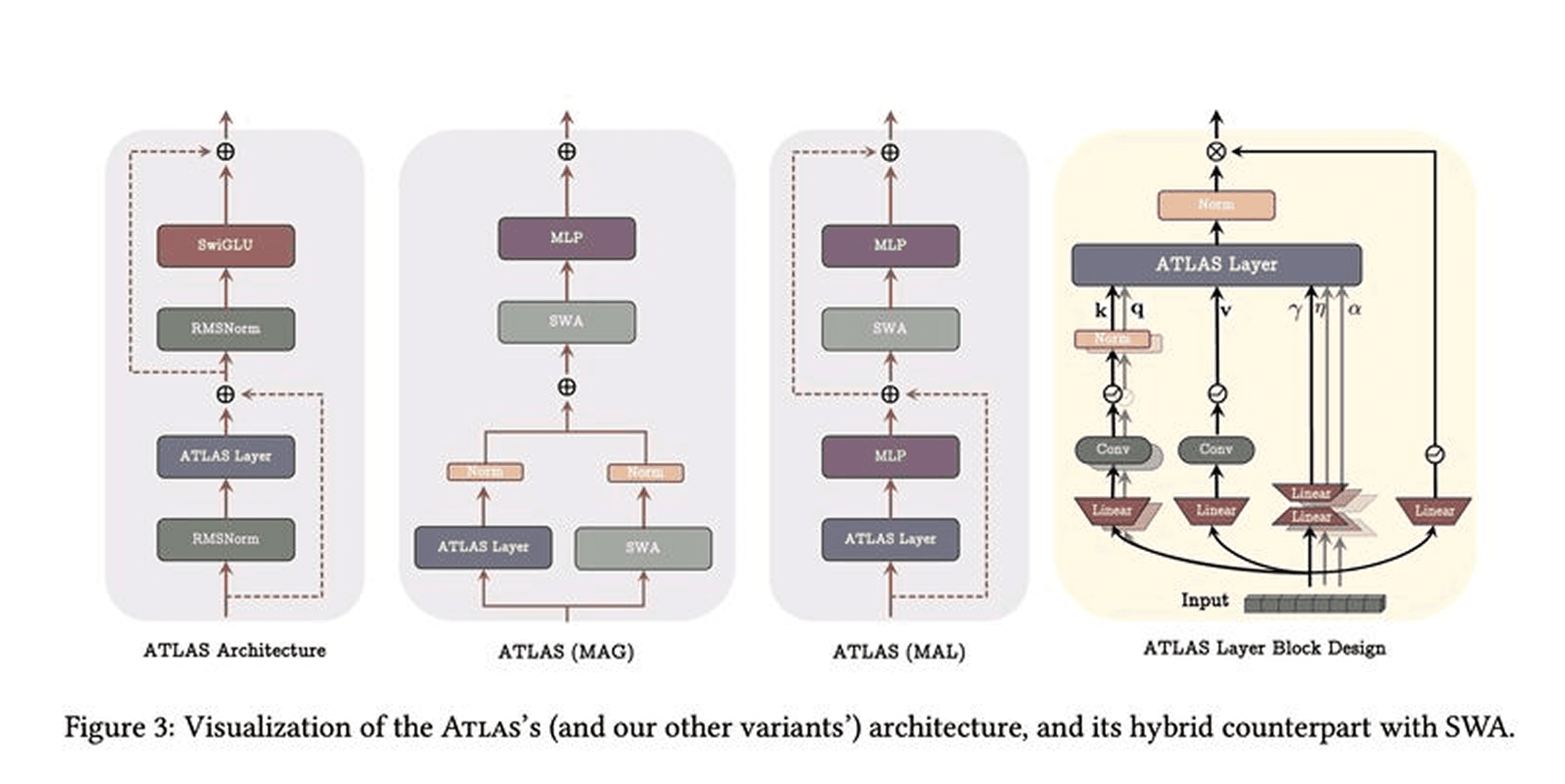
Atlas: Learning to Optimally Memorize Context at Test Time
Google Research introduces Atlas, a long-term memory module designed to overcome limitations in modern recurrent neural networks for long-context understanding through innovative memory management approaches.
Key findings:
Enhanced Memory Capacity: Introduces polynomial feature mappings and deep memory modules to significantly improve memory capacity of long-term memory models like RNNs beyond traditional limitations
Omega Rule Innovation: Employs a sliding window learning approach that optimizes memory based on local context windows rather than individual tokens, enabling contextual pattern memorization
Superior Long-Context Performance: Claims to surpass Transformers and recent linear recurrent models, achieving 80% accuracy at 10M context length on the BABILong benchmark
The research presents empirical and theoretical advancements for RNN models in long-context tasks, offering a viable alternative to Transformer-based architectures for extended sequence modeling.
Read Our TuesdayPaperThoughts analysis
Qwen3 Technical Report: Unified Model Design for Multi-Modal Reasoning
Alibaba's Qwen team releases a comprehensive technical report on Qwen3, showcasing a unified model architecture that seamlessly integrates rapid-response and multi-step reasoning capabilities within a single framework.
Key findings:
Unified Flexible Modes: Integrates thinking and non-thinking modes with dynamic switching based on query complexity, supporting 119 languages across 0.6B to 235B parameters with efficient MoE activation (22B per token)
Large-Scale Multi-Stage Training: Trained on 36T tokens using a 3-stage strategy combining general, STEM-heavy, and long-context data, supporting sequences up to 32K tokens with synthetic data from Qwen2.5 variants
Efficient Post-Training Pipeline: Combines CoT fine-tuning, reinforcement learning, and unified alignment, with smaller models using strong-to-weak distillation that outperforms RL in both performance and training costs
Qwen3 achieves top-tier performance on AIME'25 (81.5), LiveCodeBench (70.7), and CodeForces (2,056), significantly narrowing the gap with proprietary models while being openly released under Apache 2.0.
Read Our TuesdayPaperThoughts analysis

Looking Forward
As we witness this rapid pace of model improvements from both established players and emerging competitors, it's clear the LLM landscape is becoming increasingly competitive. However, Builder.ai's deceptive practices serve as a reminder that transparency and genuine innovation matter more than hype.
Looking ahead, we're particularly excited about the convergence of reasoning capabilities and practical applications, especially in specialized domains like Pharma, where context and accuracy are paramount.
If you're exploring how to leverage these advances for your specific use case, we'd love to hear from you.



