
Dear Readers,
Welcome to the 20th edition of Fine-Tuned by Genloop! November has been an incredible month for us—we're thrilled to share that Genloop received some significant recognition in the industry, including winning "Most Innovative Product" at NetApp Demo Day and being named a Top 30 Tech Startup by YourStory. More on these milestones below!
On the AI front, the past two weeks brought major releases across the board. Moonshot AI open-sourced Kimi K2 with breakthrough agentic capabilities, OpenAI upgraded to GPT-5.1 with warmer tone and adaptive reasoning, and we explore how AI capabilities doubling every 6 months could break 150 years of GDP growth trends.
Let's dive in!
🌟 AI Industry Highlights
Moonshot AI Releases Kimi K2: Open-Source MoE Model for Agentic Tasks
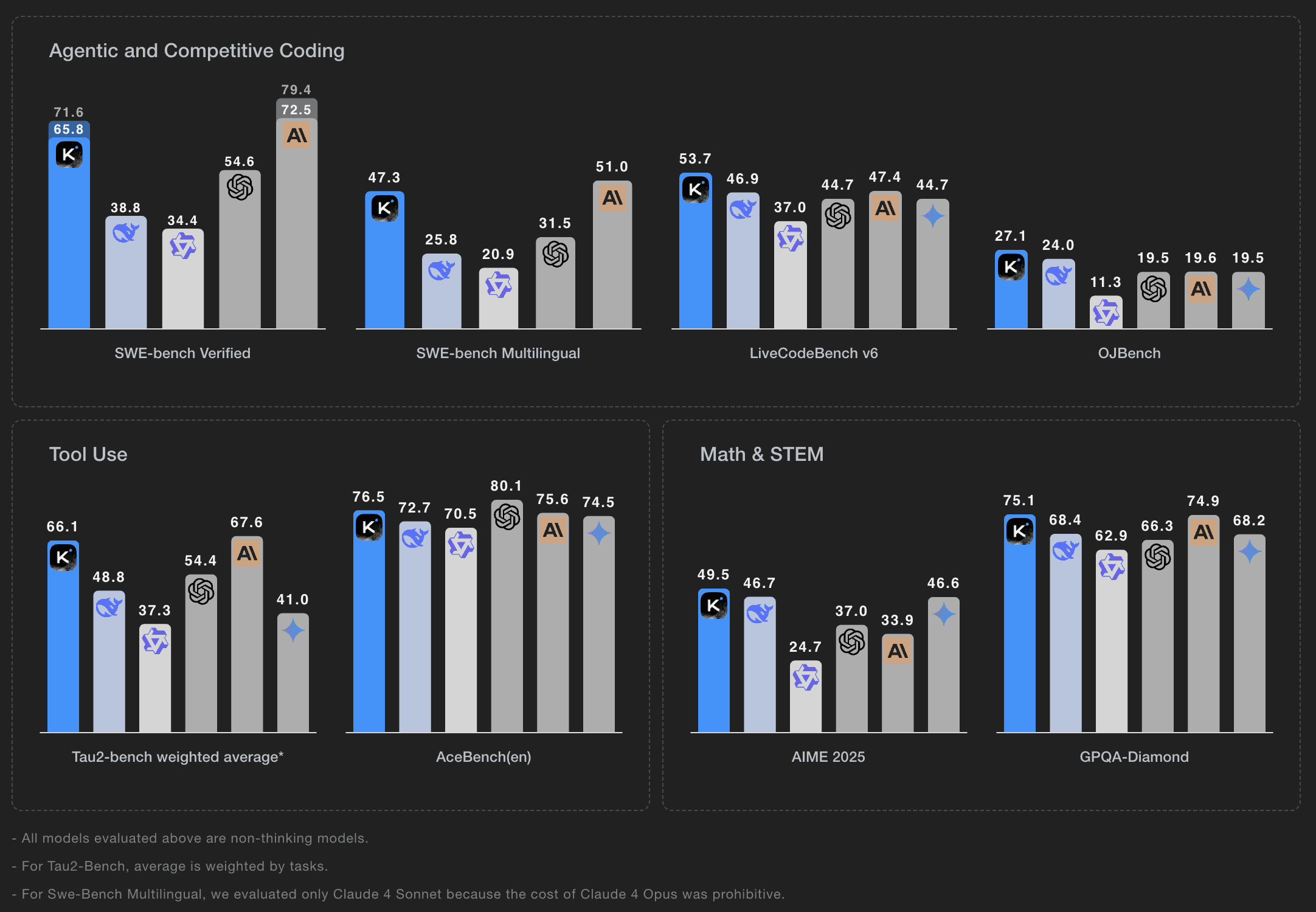
Moonshot AI open-sourced Kimi K2, a Mixture-of-Experts model with 32B activated parameters and 1T total parameters, achieving state-of-the-art performance on coding, math, and tool use among non-thinking models.
Key highlights:
Strong Agentic Performance: Achieves 65.8% on SWE-bench Verified (agentic coding), 53.7% on LiveCodeBench v6, 49.5% on AIME 2025, and 75.1% on GPQA-Diamond—outperforming DeepSeek-V3 and Qwen3-235B across most benchmarks
MuonClip Optimizer: Introduces MuonClip with qk-clip technique that controls attention logit explosions, enabling zero training spikes across 15.5T tokens for stable large-scale training
Agentic Capabilities: Large-scale data synthesis pipeline with MCP tools and general RL system using self-judging mechanism for both verifiable (math, coding) and non-verifiable tasks (reports, writing)
Available as Kimi-K2-Base and Kimi-K2-Instruct with 256K context support under open-source license.
OpenAI Releases GPT-5.1: Warmer Tone, Adaptive Reasoning, and Better Instruction Following
OpenAI upgraded the GPT-5 series with GPT-5.1 Instant and GPT-5.1 Thinking, making ChatGPT warmer, more conversational, and significantly better at following instructions while introducing new customization controls for tone and personality.
Key highlights:
GPT-5.1 Instant with Adaptive Reasoning: Most-used model now warmer by default and can decide when to think before responding on challenging questions—achieving significant improvements on AIME 2025 and Codeforces while maintaining quick responses for simple queries
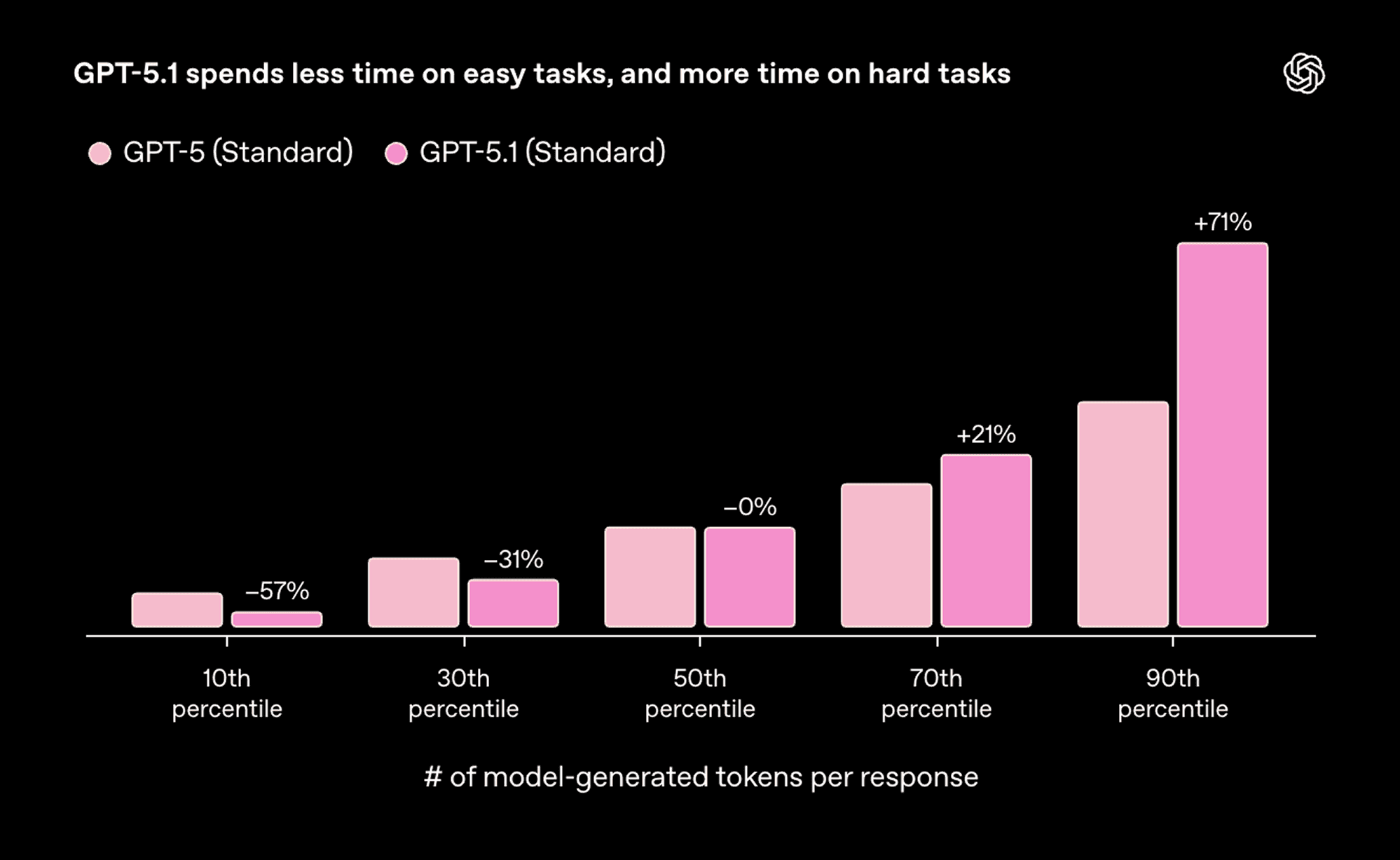
GPT-5.1 Thinking Efficiency: Adapts thinking time dynamically—roughly 2x faster on simplest tasks (57% fewer tokens at 10th percentile) and 2x slower on hardest tasks (71% more tokens at 90th percentile)—with clearer responses using less jargon for complex technical concepts
Enhanced Personalization: Six preset styles (Default, Professional, Friendly, Candid, Quirky, Efficient) plus experimental fine-tuning controls for conciseness, warmth, scannability, and emoji frequency—changes apply across all chats immediately, with improved adherence to custom instructions
Rolling out gradually starting with paid users (Pro, Plus, Go, Business), then free users. GPT-5 models remain available for 3 months under legacy dropdown for comparison.
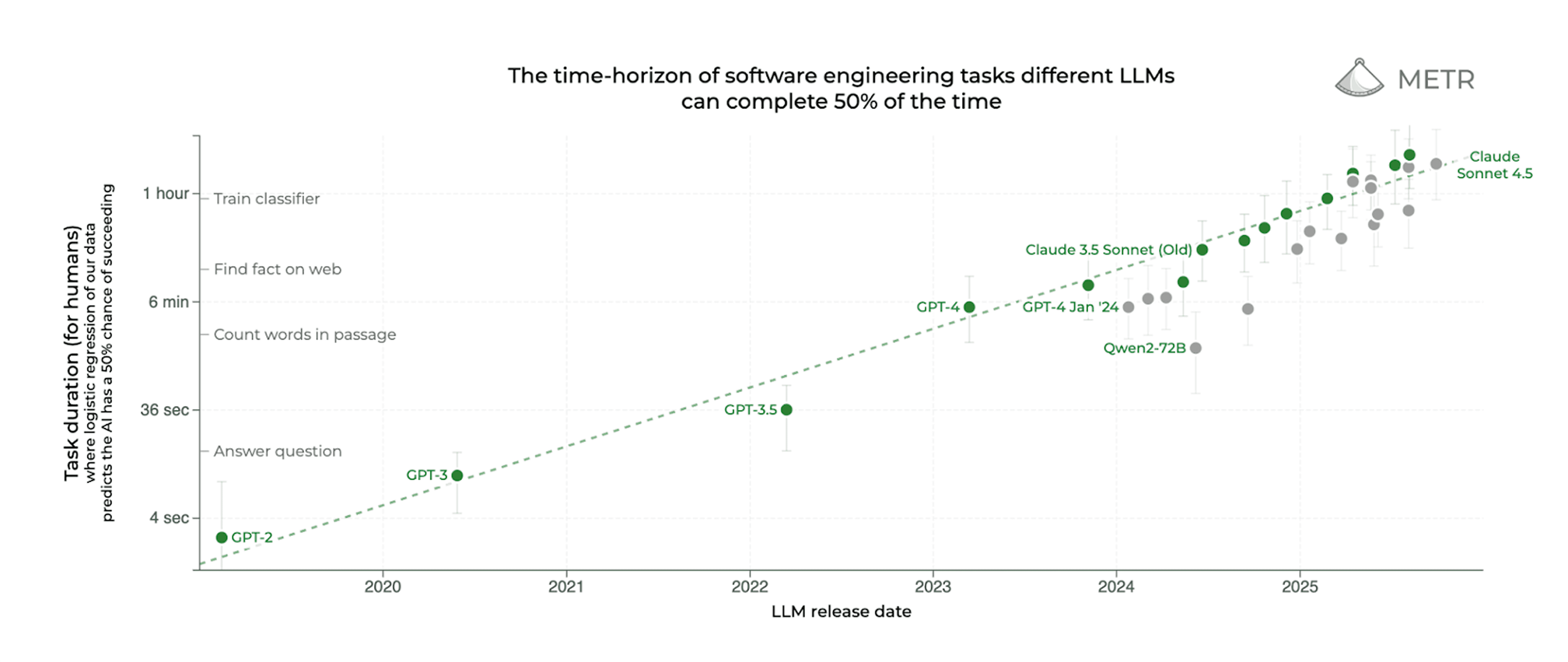
AI Capabilities Doubling Every 6 Months Could Break 150-Year GDP Growth Trend
Computer scientist Boaz Barak analyzed METR research showing AI task-completion horizons doubling every 6 months—even at 9% annual automation (far below current 75% trends), models predict 10x productivity within two decades, potentially breaking the 2% GDP growth constant through 150 years of electricity, computers, and internet.
Key highlights:
Exponential Capability Growth: METR data shows AI time horizons quadrupling yearly with 50% success rate; even at 100% reliability, similar doubling time persists—suggesting once AI automates half the tasks in an industry, it could reach 97% automation within 2 years
Cost Collapse Enables Scale: Inference costs dropping 10x annually means once a job is automated, AI cost to perform it becomes negligible within a year—though physical robotics may not follow same cost trajectory as virtual assistants
Transformative Growth Threshold: Using B. Jones' harmonic mean model, even conservative 9% annual automation rate combined with 10x yearly productivity gains could achieve 10x productivity (transformative AI) within 10-20 years—far exceeding Acemoglu's 0.1% or Goldman Sachs' 1.5% GDP growth predictions
Critical assumption: exponential capability growth must translate to exponential task automation—historical automation has been linear with single-digit rates, making this a potential break from 80 years of trends.
✨ Genloop Wins "Most Innovative Product" by NetApp & Named Top 30 Tech Startup by YourStory
November has been an incredible month for us! We're thrilled to share that Genloop was recognized as the Most Innovative Product at NetApp Excellerator Cohort 14—a program bringing together top startups solving enterprise-scale problems alongside NetApp's global leadership and mentors.

The recognition validates what we've been building: a solution to the fundamental problem that over 80% of business questions fall outside static dashboards today. When 55% of data experts say it takes them more than a week to complete a single request, the moment of decision has often passed. That's why 1 in 5 business decisions is still made on gut, not data.
We're proud to be delivering quality insights in seconds for the most complex, high-accuracy data environments where precision and reliability truly matter. We've been quietly building under the radar with a soft launch alongside our early customers—stay tuned for our formal rollout in the coming weeks.
We were also honored to be named one of the Top Tech 30 Startups by YourStory at TechSparks 2025, further affirming our mission to make every enterprise truly data-driven.
It's been an amazing ride, and we're just getting started.
🔬 Research Corner
Check out the top papers of the week on LLM Research Hub. Each week, our AI agents scour the internet for the best research papers, evaluate their relevance, and our experts carefully curate the top selections.
Don't forget to follow us to stay up to date with our weekly research curation!
Now, let's deep dive into the top research from the last two weeks:
IMO-Bench: Moving Beyond Answer-Guessing to Real Mathematical Reasoning
Google DeepMind introduces IMO-Bench as popular benchmarks like GSM8K and MATH approach saturation. Existing evaluations lack sufficient difficulty and measure only final answers rather than genuine reasoning depth—this benchmark addresses both gaps.
Key findings:
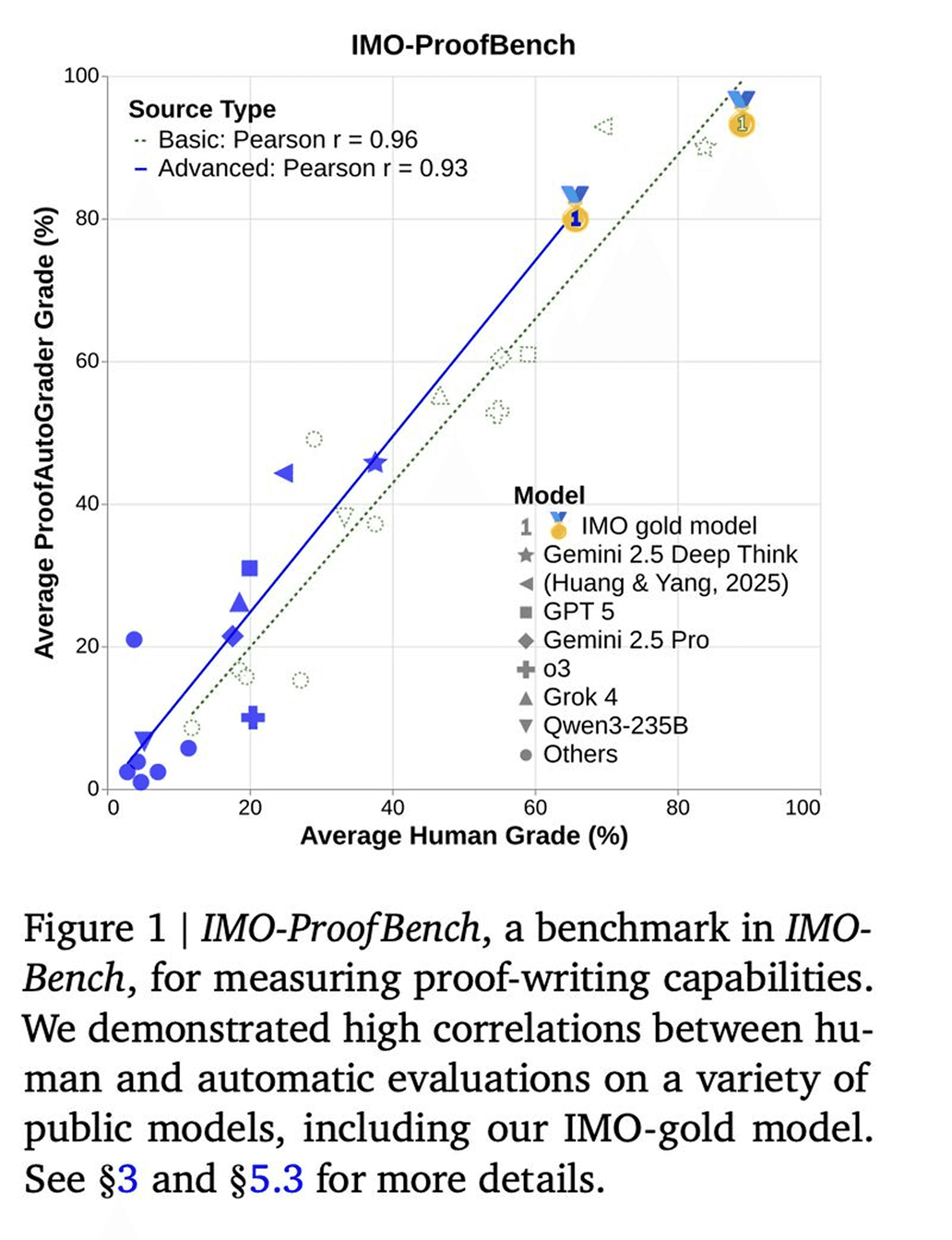
Three-Tiered Benchmark Suite: IMO-AnswerBench (400 robustified Olympiad problems), IMO-ProofBench (60 proof-writing problems at basic and advanced levels), and IMO-GradingBench (1000 human-graded solutions)—all vetted by IMO medalists and modified to eliminate memorization
Real-World Validation at IMO 2025: Gemini Deep Think achieved 80.0% on IMO-AnswerBench and 65.7% on advanced IMO-ProofBench, outperforming best non-Gemini models by 6.9% and 42.4%; most frontier models scored below 25% on proof problems, revealing how answer-only evaluation masks reasoning gaps
Scalable Automated Evaluation: AnswerAutoGrader achieves 98.9% accuracy vs human evaluations, ProofAutoGrader maintains 0.93-0.96 correlation with expert scores—addressing the costly bottleneck of human expert evaluation
With FrontierMath already highlighting limitations of answer-matching approaches, IMO-Bench's emphasis on complete proofs represents the direction needed to measure true mathematical reasoning capability.
Read Our TuesdayPaperThoughts analysis
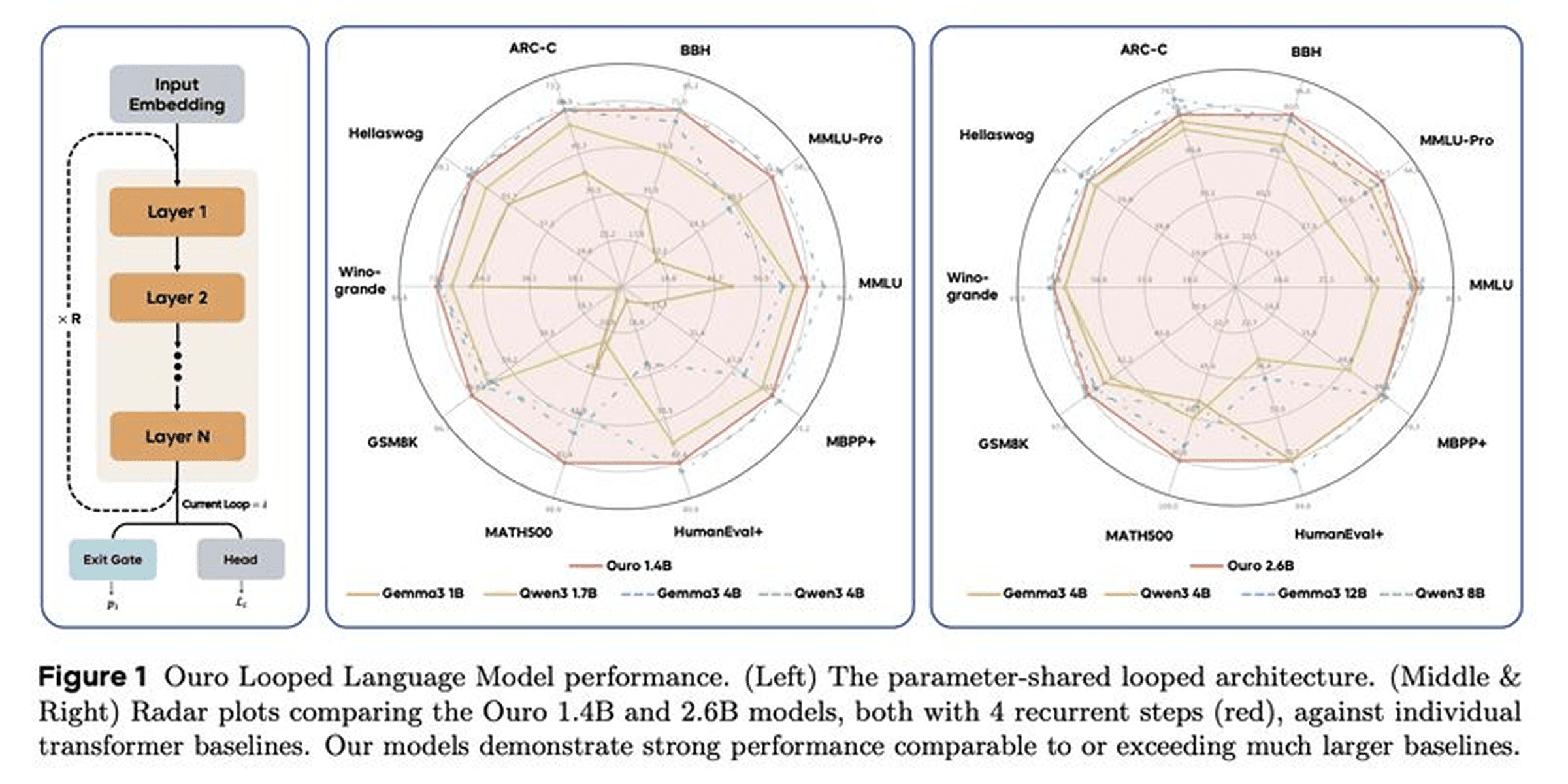
Ouro: 2-3× Parameter Efficiency Through Recursive Computation
ByteDance and researchers from UC Santa Cruz, Princeton, Mila, CMU, and UPenn introduce Ouro, achieving 2-3× parameter efficiency by recursively reusing weight-shared layers. Models process inputs iteratively without expanding parameter count—enabling deeper computation on-demand rather than through static depth.
Key findings:
Exceptional Parameter Efficiency: 1.4B and 2.6B Ouro models match 4B and 8B standard transformers across benchmarks—on MATH500, Ouro-1.4B achieves 82.4% vs 59.6% for Qwen3-4B, while Ouro-2.6B reaches 90.9% vs 62.3% for Qwen3-8B, validated across 7.7T tokens of training
Knowledge Manipulation Over Storage: Recurrence doesn't increase parametric knowledge capacity (both looped and standard models store ~2 bits per parameter), but dramatically enhances knowledge manipulation on multi-hop reasoning and fact composition with superior sample efficiency—gains come from better parameter utilization, not storing more facts
Adaptive Computation with Safety: Entropy-regularized training with uniform prior enables learned early exit—simple inputs terminate after fewer steps while complex ones allocate more iterations, achieving near-linear computational scaling while outperforming significantly larger models
Could adaptive computation be the next frontier after we've exhausted parameter and data scaling?
Read Our TuesdayPaperThoughts analysis
Looking Forward
This fortnight's releases paint a picture of AI reaching an inflection point. From Kimi K2's breakthrough in agentic capabilities to OpenAI making GPT-5.1 more conversational and adaptive, we're seeing models that don't just answer questions—they act, reason dynamically, and communicate naturally.
The infrastructure is catching up too, with custom kernels enabling trillion-parameter deployments and efficiency gains making powerful AI accessible beyond well-funded teams.



