Dec 18, 2025

Dear Readers,
Welcome to the 22nd edition of Fine-Tuned by Genloop! The past two weeks have brought major developments across the AI landscape—from OpenAI's GPT-5.2 launch and enterprise adoption data showing surprising gaps, to NVIDIA's efficiency-focused approach with Nemotron 3 Nano and an unexpected alliance between OpenAI, Anthropic, and Block.
Enterprise AI spending hit $37 billion in 2025, growing faster than any software category in history, while OpenAI's own report reveals frontier workers are extracting 6x more value than their median peers, highlighting a widening productivity divide.
Let's dive in.
🌟 AI Industry Highlights
NVIDIA Nemotron 3 Nano: Redefining Efficiency in Open Models
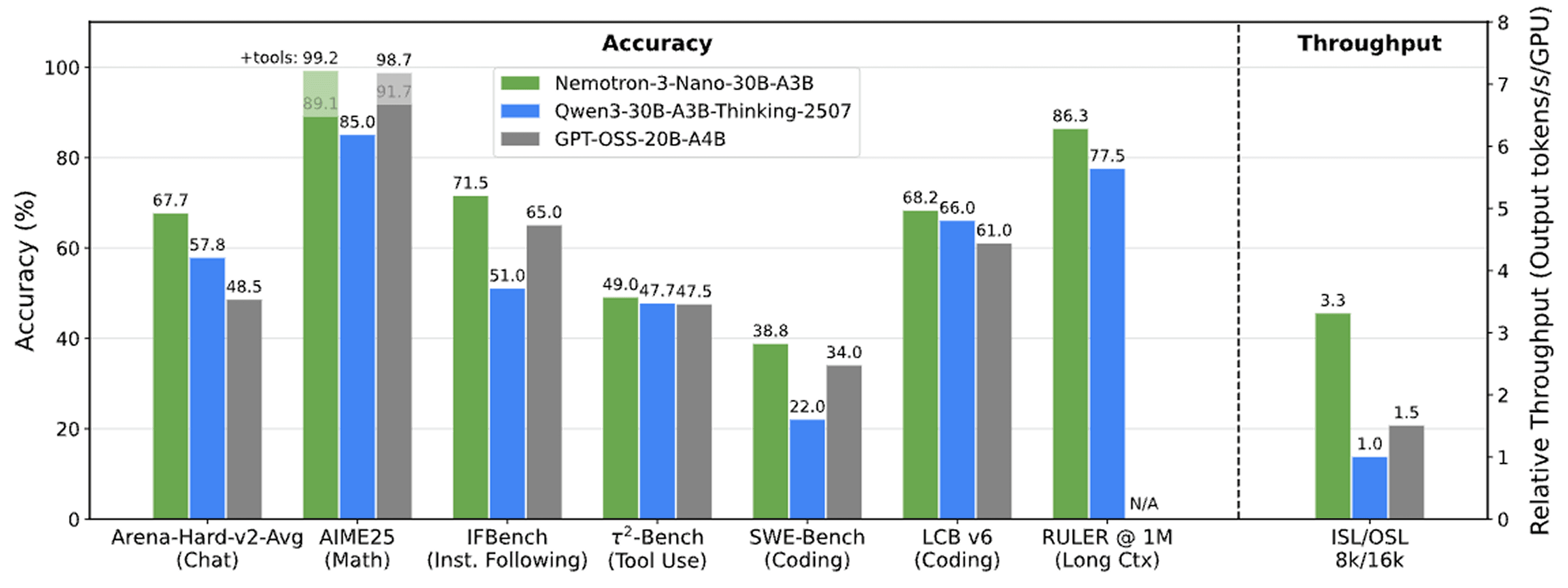
While Chinese labs have been dominating the open source AI leaderboard, NVIDIA took a different approach with Nemotron 3 Nano—not chasing the biggest parameter count, but building what might be the smartest architecture for production systems.
Key highlights:
Hybrid efficiency breakthrough: 30B parameter model activates only 3.2B parameters per token, delivering up to 3.3x higher throughput than comparable open models at roughly 377 tokens per second.
Strong real-world performance: Bronze-medal on International Mathematical Olympiad benchmarks, 1M token context windows, runs on just 25GB RAM.
Complete transparency: Full training recipe released including 3 trillion tokens of pretraining data, post-training datasets, RL environments, and infrastructure code.
The release came alongside a coordinated wave of open models on Monday, including Allen AI's OLMo 3.1, Bolmo's byte-level tokenisation, and Arcee AI's DistillKit.
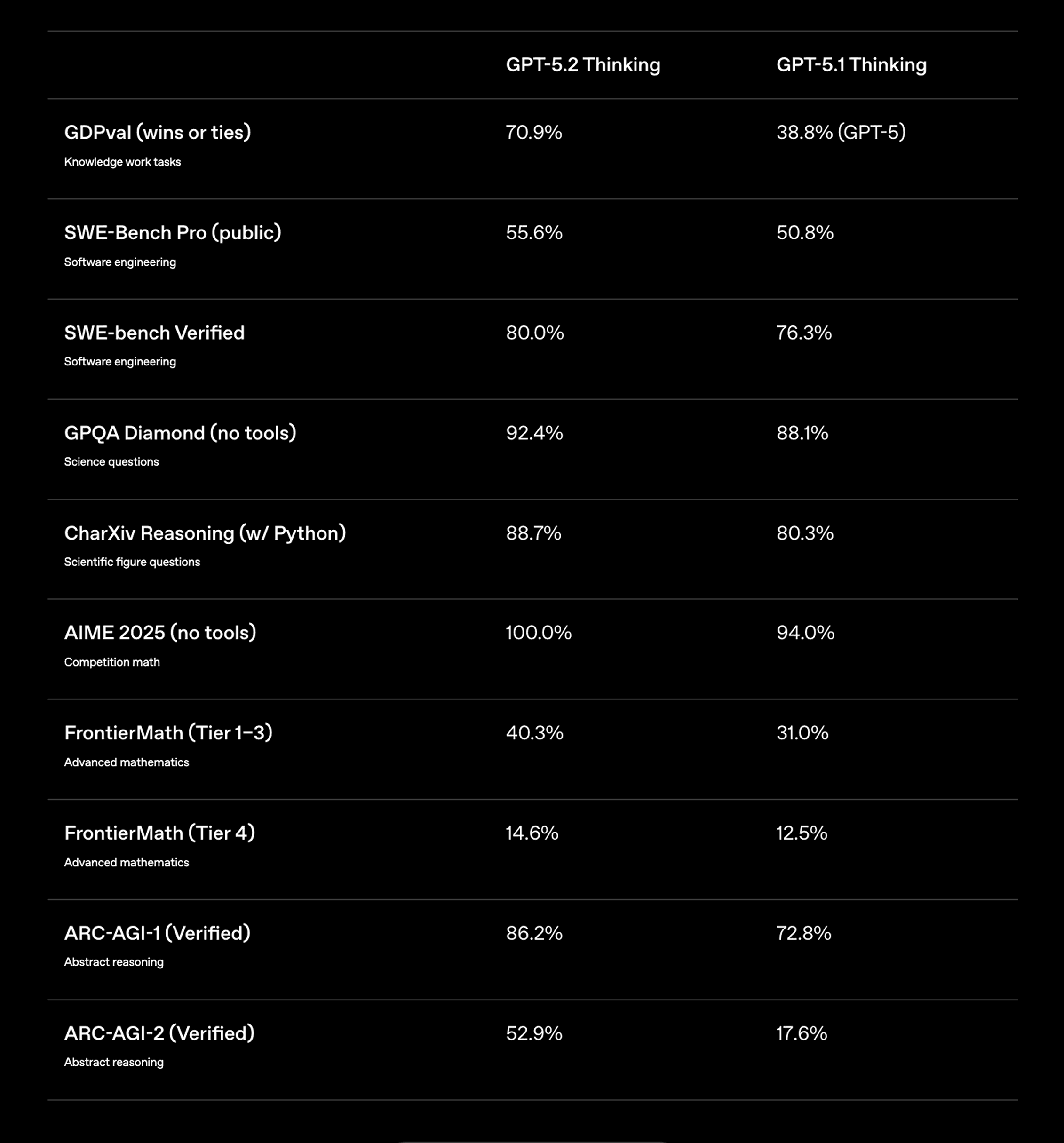
OpenAI Releases GPT-5.2: Built for Professional Work and Agentic Systems
OpenAI launched GPT-5.2, their most capable model yet for professional knowledge work, claiming it outperforms industry experts on 70.9% of tasks spanning 44 occupations while operating at 11x the speed and less than 1% the cost.
Key highlights:
Professional performance leap: State-of-the-art on real-world knowledge work tasks, 55.6% on SWE-Bench Pro, 80% on SWE-bench Verified, plus new spreadsheet and presentation generation in ChatGPT.
Stronger reliability: 30% reduction in hallucinations, near-perfect long-context accuracy up to 256k tokens, 50% fewer errors on chart reasoning and UI understanding.
Variants: Available in three variants—Instant, Thinking, and Pro—now in ChatGPT paid plans and API. Priced at $1.75/1M input tokens, $14/1M output tokens.
The reviews are however mixed, which some calling it quite a letdown. This is also more expensive than GPT-5.1, breaking the observation again that newer models are most cost efficient.
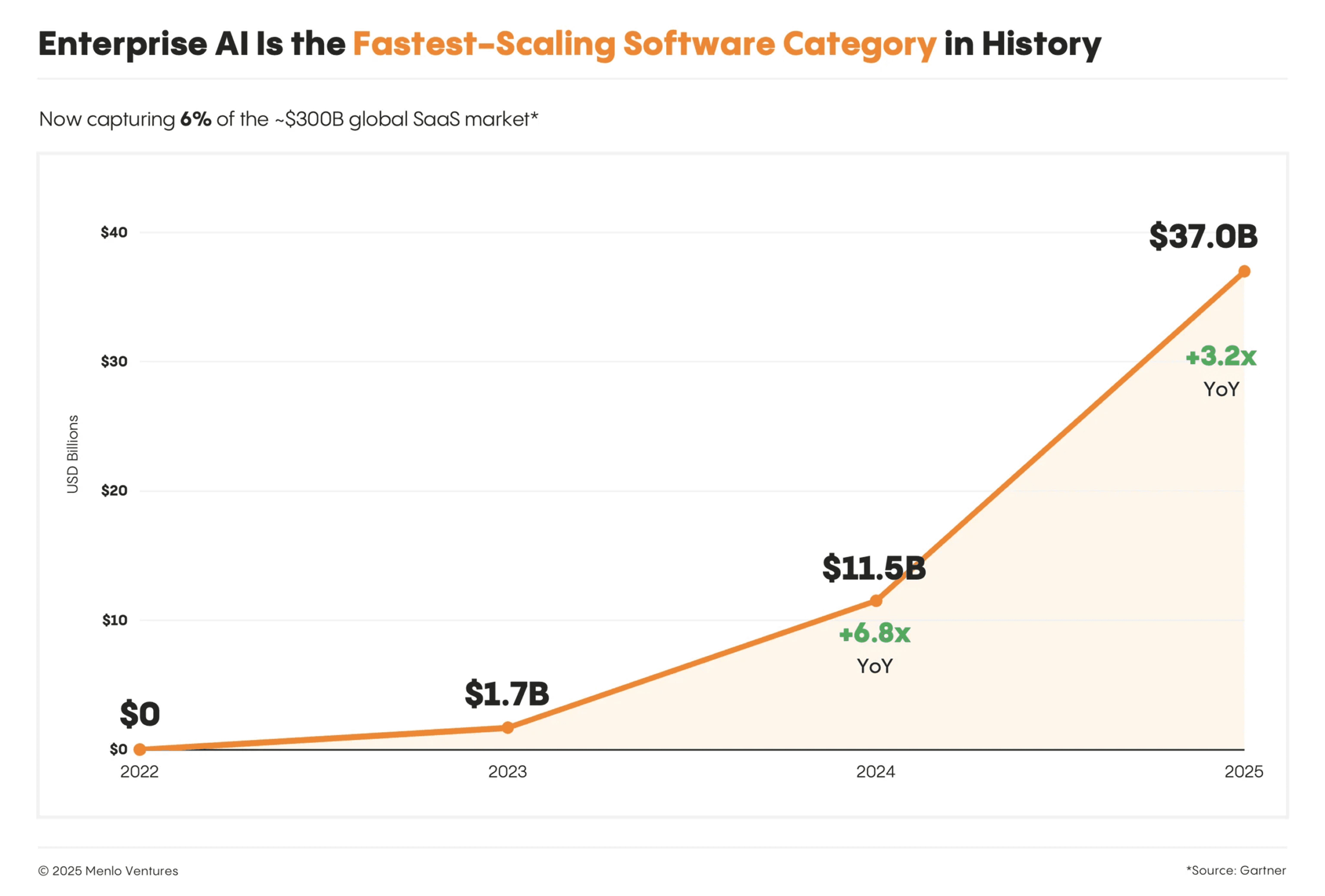
Menlo Ventures: Enterprise AI Hits $37B, Growing Faster Than Any Software Category in History
Menlo Ventures' 2025 report reveals enterprise AI spending reached $37 billion (up 3.2x from $11.5B in 2024), capturing 6% of the global SaaS market just three years after ChatGPT's launch—contradicting fears of an AI bubble.
Key highlights:
Enterprises prefer buying over building: 76% of AI solutions are now purchased vs. 47% last year, with AI deals converting at 47% vs. traditional SaaS at 25%.
Startups are beating incumbents: Startups captured 63% of application layer revenue vs. incumbents' 37%, led by categories like product/engineering (71% startup share) and sales (78% startup share).
Anthropic leads enterprise LLM market: Commands 40% enterprise spend (up from 24% last year), with 54% share in coding. OpenAI fell to 27% from 50% in 2023, while Google rose to 21% from 7%.
🔬 Research Corner
Check out the top papers of the week on LLM Research Hub. Each week, our AI agents scour the internet for the best research papers, evaluate their relevance, and our experts carefully curate the top selections.
Don't forget to follow us to stay up to date with our weekly research curation!
Now, let's deep dive into the top research from the last two weeks:
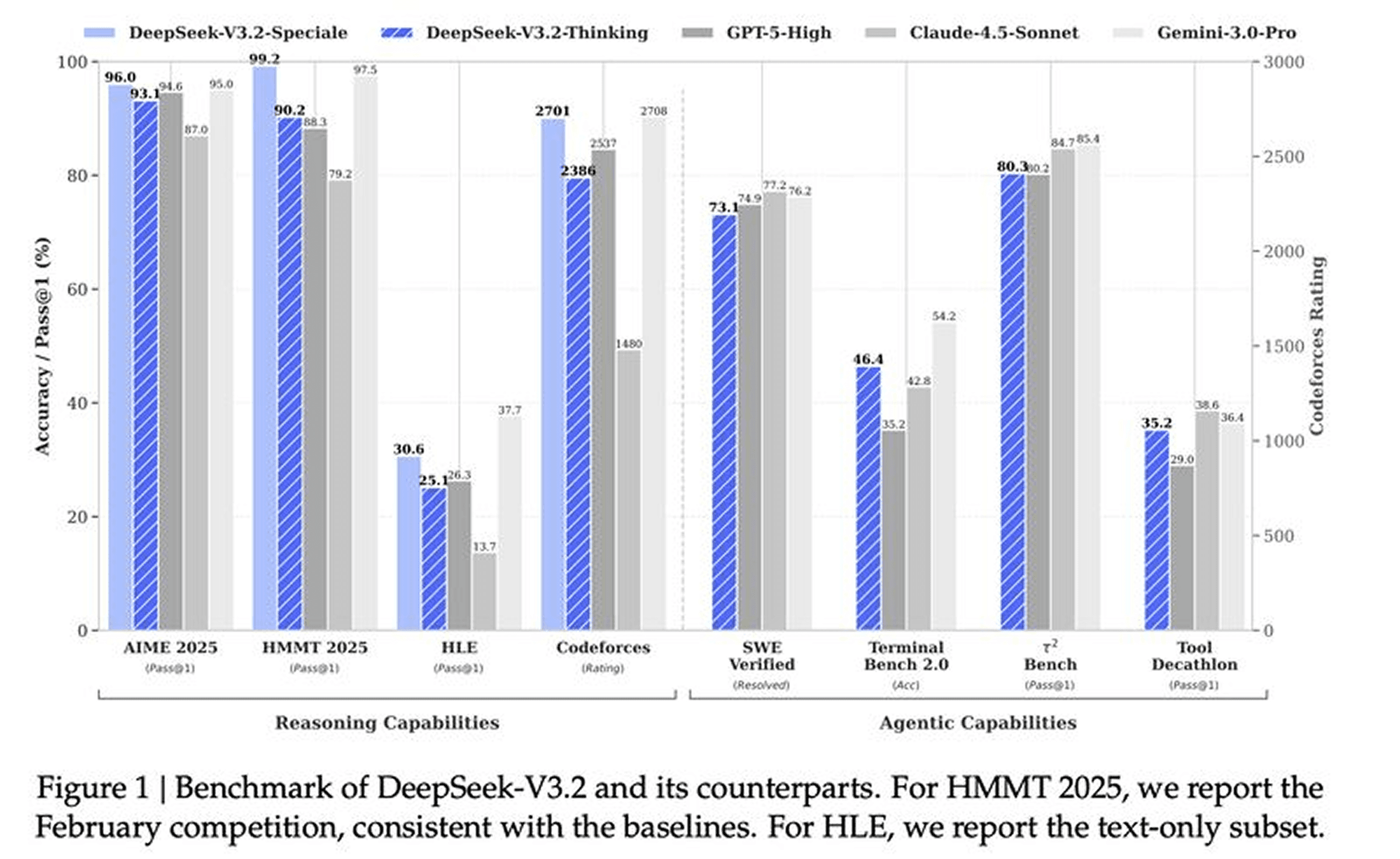
DeepSeek-V3.2: Scaling Post-Training to Match GPT-5 Performance
DeepSeek's latest work introduces architectural innovations and massive post-training compute (over 10% of pre-training budget) to achieve GPT-5-level reasoning while maintaining efficiency in long-context scenarios.
Key findings:
DeepSeek Sparse Attention (DSA): Tackles quadratic complexity O(L²) with a lightning indexer for fine-grained token selection, reducing core attention to O(Lk). Delivers 40-60% cost reduction at 128K tokens without performance loss.
Massive Post-Training Investment: Allocates over 10% of pre-training compute to post-training phase, achieving GPT-5-comparable reasoning performance. High-compute variant DeepSeek-V3.2-Special reaches gold medal level on IMO 2025 and IOI 2025.
Thinking Context in Tool-Use: Retains reasoning trace while waiting for tool results, combined with large-scale agentic task synthesis (1,800+ environments, 85,000+ prompts). Significantly narrows open vs. closed-source gap on agent benchmarks like MCP-Universe and Tool-Decathlon.
DeepSeek demonstrates that sufficient post-training investment, paired with architectural efficiency, can close capability gaps—providing both the foundation and empirical proof for efficient scaling.
Read the TuesdayPaperThoughts analysis
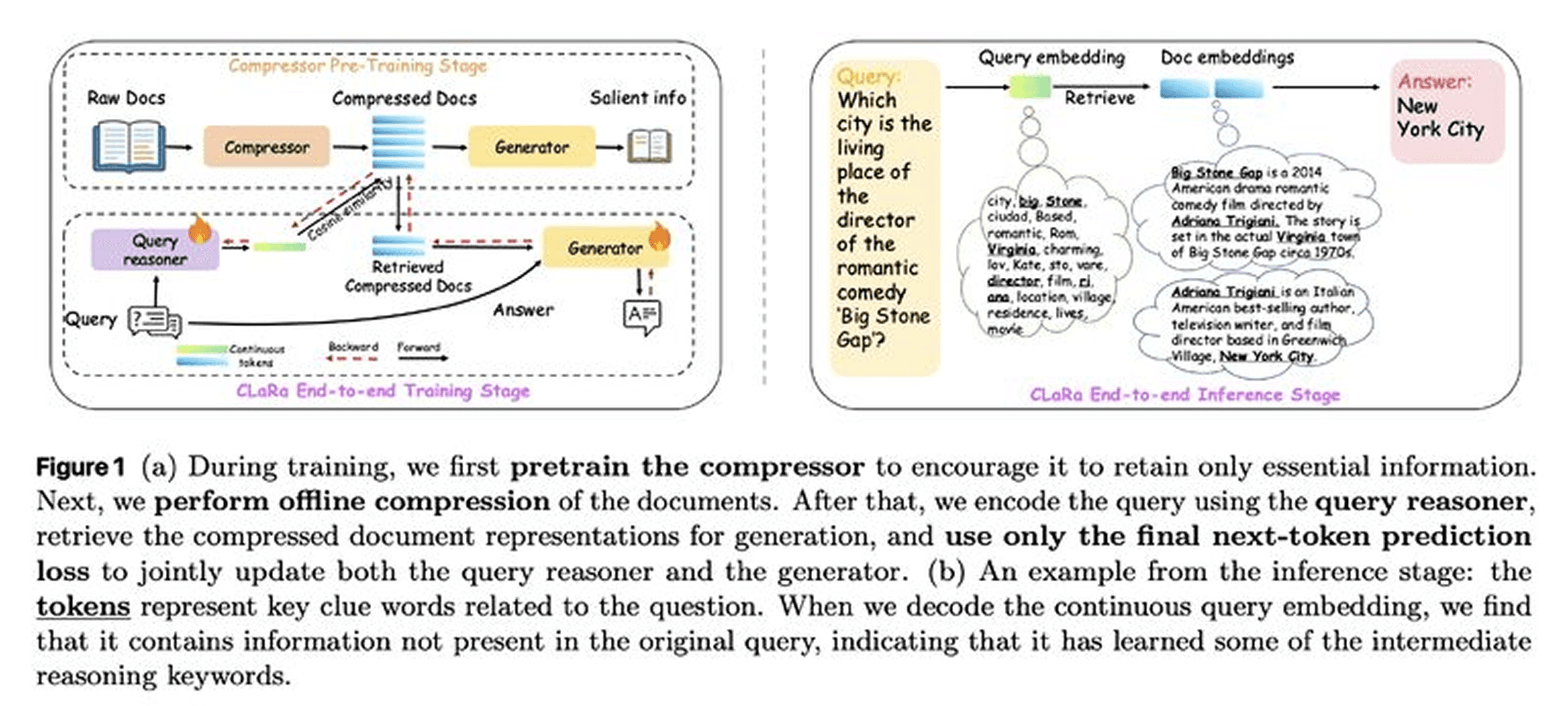
CLaRa: Unifying Retrieval and Generation Through Continuous Latent Reasoning
Apple and University of Edinburgh researchers introduce CLaRa, a framework that unifies retrieval and generation in a single differentiable architecture, addressing the fundamental flaw in traditional RAG systems where retrieval and generation operate separately.
Key findings:
Salient Compressor Pre-training (SCP): Uses QA-driven and paraphrase-based data synthesis to train the compressor, focusing on semantic essentials rather than token-by-token reconstruction. Compressed representations outperform text-based baselines by 2.36% on Mistral-7B using 16× less context.
Weakly Supervised Joint Training: Trains query reasoner and generator end-to-end using only next-token prediction loss with gradients flowing through differentiable top-k estimator. No relevance labels needed—directly aligns retrieval relevance with answer quality.
Strong Empirical Results: On HotpotQA with 4× compression, achieves 96.21% Recall@5, exceeding fully supervised BGE-Reranker (85.93%) by +10.28%. Proves joint optimization with weak supervision can outperform explicit retrieval training.
CLaRa challenges the standard RAG architecture by demonstrating that unified, end-to-end optimization can surpass traditional two-stage approaches without manual relevance labels.
Read the TuesdayPaperThoughts analysis
Looking Forward
The past two weeks paint a clear picture: AI is moving from experimentation to production at unprecedented speed, but the gap between leaders and laggards is widening fast. Enterprise spending is accelerating, open-source innovation is thriving alongside closed models, and the industry is actively shaping standards to prevent fragmentation.
What stands out most is the shift from raw capability to strategic deployment—whether it's DeepSeek's massive post-training investment matching GPT-5 performance, or frontier workers extracting 10+ hours of productivity weekly while median users leave powerful tools untouched. The opportunity is there; execution is what separates winners from the rest.




