Nov 29, 2025

Dear Readers,
Welcome to the 21st edition of Fine-Tuned by Genloop! The last two weeks delivered some of the biggest frontier-model updates of the year. Anthropic released Opus 4.5 with major gains in coding and long-running agents, Google launched Gemini 3 with state-of-the-art reasoning and agentic workflows across its ecosystem, and xAI shipped Grok 4.1 with notable improvements in interaction quality and factual reliability.
We also saw sovereign AI take center stage at the India Global Forum, where Genloop joined leaders discussing how nations can build secure and resilient AI stacks. And in research, NVIDIA and Meta pushed the boundaries again with new architectures for speed, consistency, and zero-retraining performance.
Let’s dive in
🌟 AI Industry Highlights
Claude Released Opus 4.5
Anthropic released Claude Opus 4.5, its newest frontier-grade model focused on coding, agents, and long-running computer-use tasks. The update brings improvements across reasoning, vision, math, and safety, with better performance on enterprise workflows and stronger robustness to prompt-injection.
Key highlights:
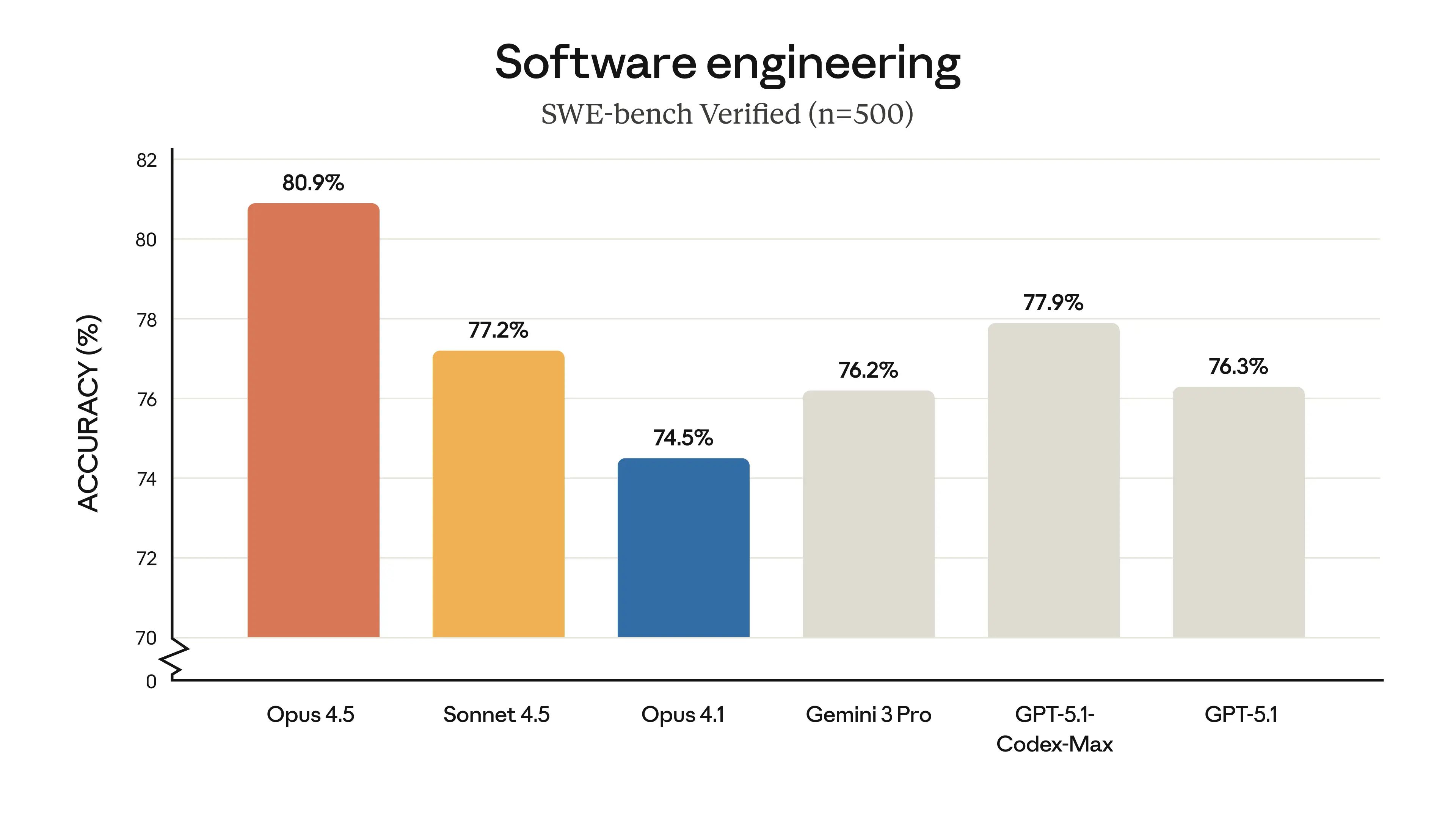
State-of-the-art engineering performance: Leads SWE-bench and improves across reasoning, math, and vision benchmarks, with significantly fewer tokens required for complex tasks.
Developer controls & agentic workflows: Adds effort control, context compaction, advanced tool use, and improved multi-agent coordination for longer, more reliable workflows.
Product updates across the Claude ecosystem: Supports longer conversations with automatic summarization, improved Claude Code with plan mode, new Chrome and Excel integrations, and expanded access across cloud platforms.
Claude Opus 4.5 signals Anthropic’s push toward more capable, efficient, and safer enterprise models—especially for engineering-heavy and multi-step workflows.
Gemini 3.0 Release
Google introduced Gemini 3, its most capable multimodal and agentic model yet, now shipping across Search (AI Mode), the Gemini app, Vertex AI, AI Studio, and Google’s new agentic development platform, Antigravity.
Key highlights:
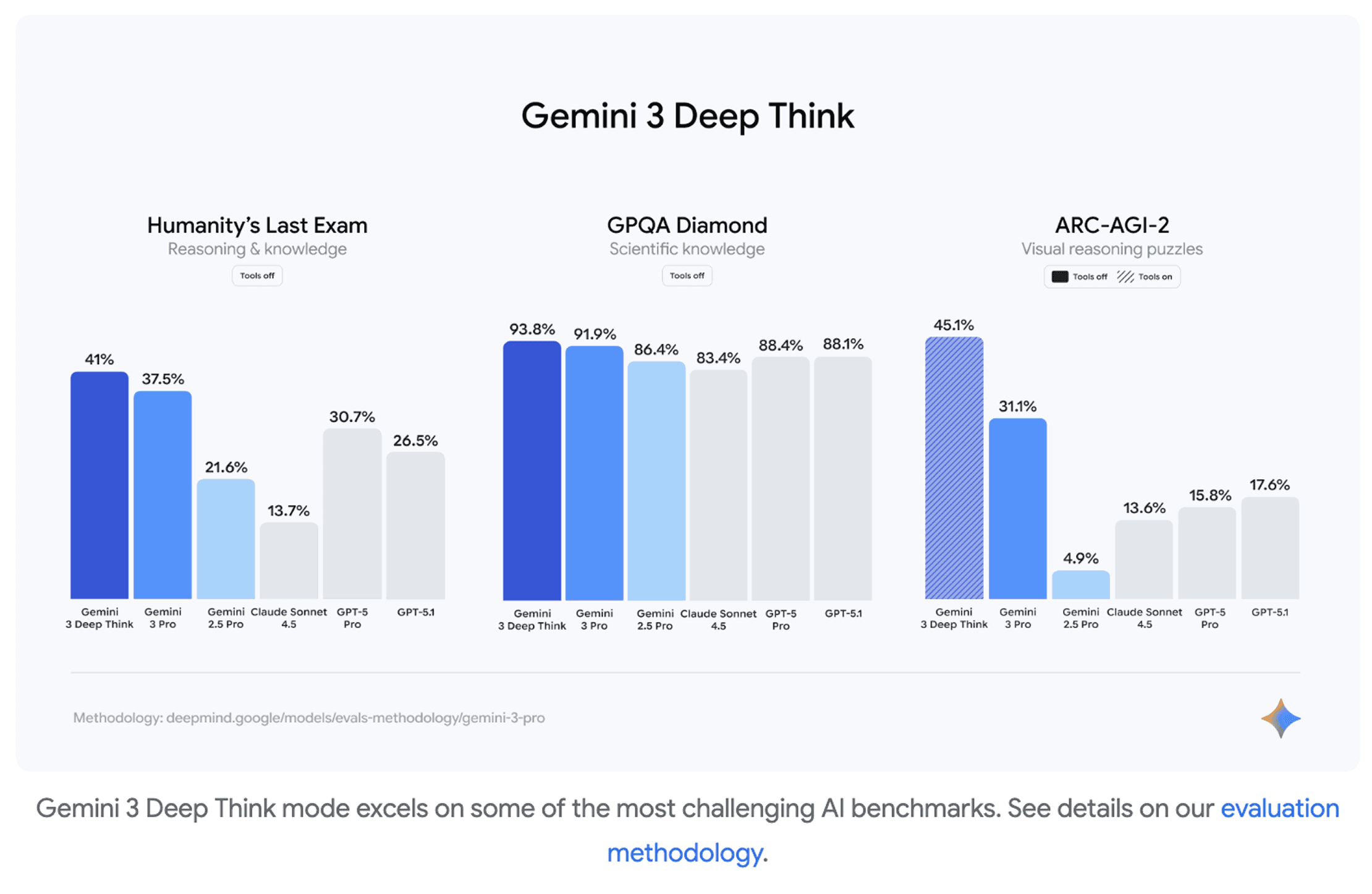
Stronger reasoning across benchmarks: Tops LMArena (1501 Elo), reaches 91.9% on GPQA Diamond, 37.5% on Humanity’s Last Exam, and sets new highs on MathArena Apex, MMMU-Pro, Video-MMMU, and SimpleQA Verified.
Deep Think mode: Enhanced reasoning variant pushing performance further — including 93.8% on GPQA Diamond and 45.1% on ARC-AGI-2 (ARC Prize Verified).
Agentic workflows + richer multimodality: 1M-token context, improved coding and tool use (54.2% on Terminal-Bench 2.0; 76.2% on SWE-bench Verified), and tighter integration into Google Antigravity for autonomous end-to-end development.
Gemini 3 marks Google’s biggest model leap yet, pairing stronger reasoning with deeper interactivity and broad product rollout. Deep Think will follow after additional safety review.
xAI launched Grok 4.1
xAI launched Grok 4.1, an update focused on real-world usability, emotional intelligence, creative writing, and reduced hallucinations. Rolled out silently between Nov 1–14, the model shows notable improvements in interaction quality and overall user preference.
Key highlights:
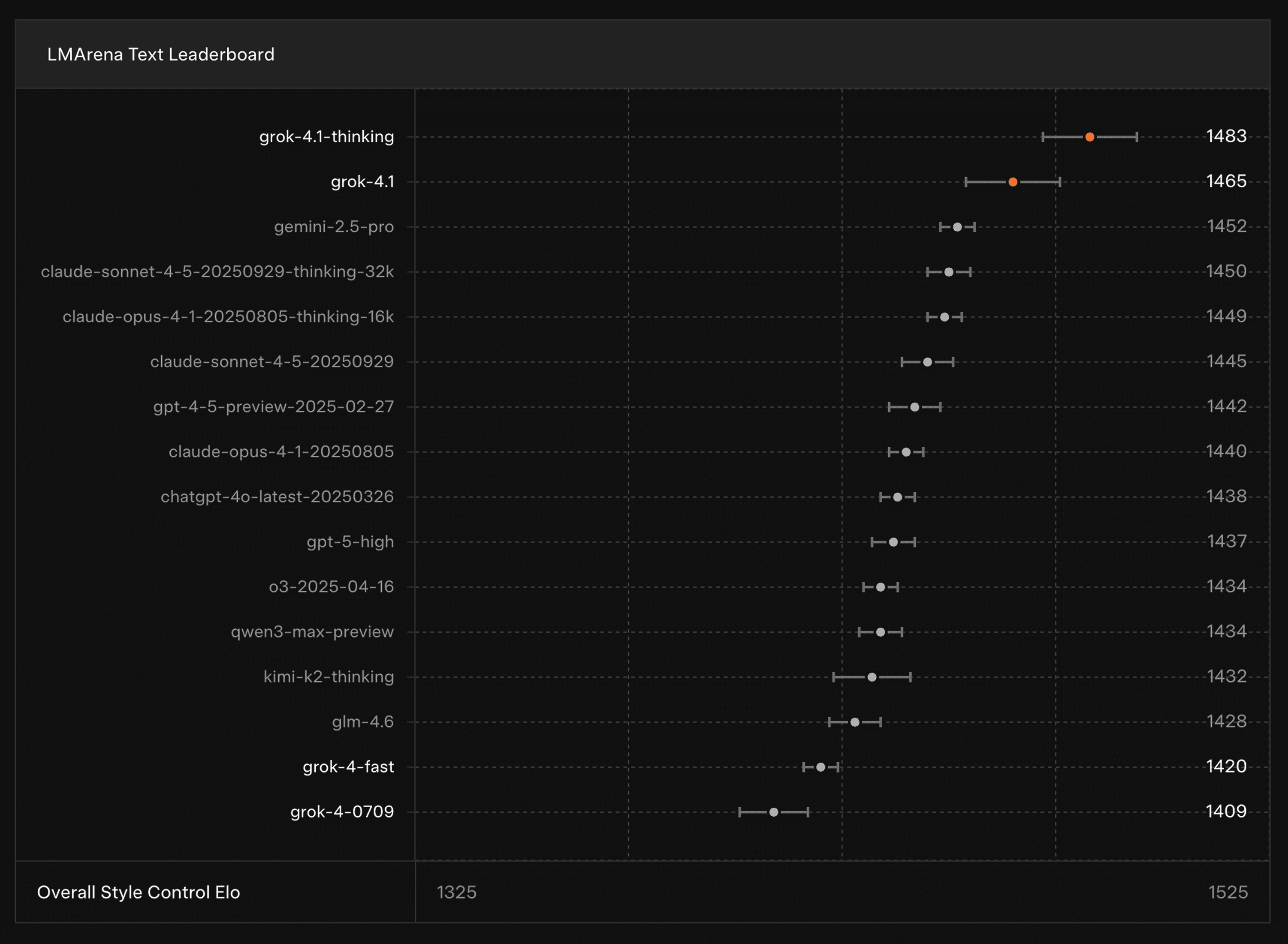
Strong preference in live evaluations: Achieves a 64.78% win rate vs the previous Grok in blind A/B traffic tests across grok.com, X, and mobile apps.
Improved reasoning modes: Offers “Thinking” mode for deeper reasoning and “Fast” mode for quick responses, with both showing strong performance on LMArena’s text leaderboards.
Better emotional intelligence & factuality: Higher EQ-Bench and Creative Writing scores, plus reduced hallucination rates when combined with web tools on real-world info-seeking prompts.
Grok 4.1 reflects xAI’s emphasis on assistant-like capabilities—better personality, clarity, and reliability—while maintaining the model’s agentic reasoning strengths.
✨ Genloop at India Global Forum 2025
Genloop’s CEO, Ayush Gupta, joined leaders at the India Global Forum: Middle East 2025 for a high-impact panel on the role of AI in emerging economies, whether nations can build their own sovereign AI stack, and how to finance and scale deep-tech innovation.
On the question of Sovereign AI, the message was clear: it is global in input and local in consequence. While fully local sourcing of the AI stack is incredibly difficult, having a plan B to safeguard national assets in adverse situations is essential. Open-weight models have played a crucial role in helping nations secure one of the most important pillars of future growth — AI intelligence and its democratization.
The energy across the Gulf nations is incredible, and Genloop is proud to have engaged with leaders shaping the future.

🔬 Research Corner
Check out the top papers of the week on LLM Research Hub. Each week, our AI agents scour the internet for the best research papers, evaluate their relevance, and our experts carefully curate the top selections.
Don't forget to follow us to stay up to date with our weekly research curation!
Now, let's deep dive into the top research from the last two weeks:
Souper-Model / SoCE: How Simple Arithmetic Unlocks SOTA Without Retraining
Meta’s latest work introduces SoCE (Soup of Category Experts), a framework that uses category-aware weight averaging to push large language models to state-of-the-art performance — without additional training.
Key findings:
Category-Driven Expert Selection:
Instead of uniform model averaging, SoCE measures Pearson correlations across benchmark categories to identify weakly correlated clusters. It then selects expert checkpoints for each cluster and combines them using optimized weighted averaging rather than simple mean soups.
SOTA Gains With Zero Retraining:
SoCE reaches 80.68% on BFCL (70B models) — a 2.7% absolute improvement over prior best. For 8B models, performance jumps 5.7% (relative) to 76.50%. These improvements come entirely from smart aggregation of existing checkpoints, not extra compute.
More Consistent, Robust Models:
Across 800+ checkpoints, souped models show higher category-wise correlations and outperform baselines on 20+ of 36 categories. The method strengthens coherence across domains, not just aggregate scores.
SoCE offers a simple but powerful recipe: strategically combine complementary checkpoints to unlock SOTA performance, making large-model improvement more accessible without full retraining cycles.
Read the TuesdayPaperThoughts analysis

TiDAR: Think in Diffusion, Talk in Autoregression
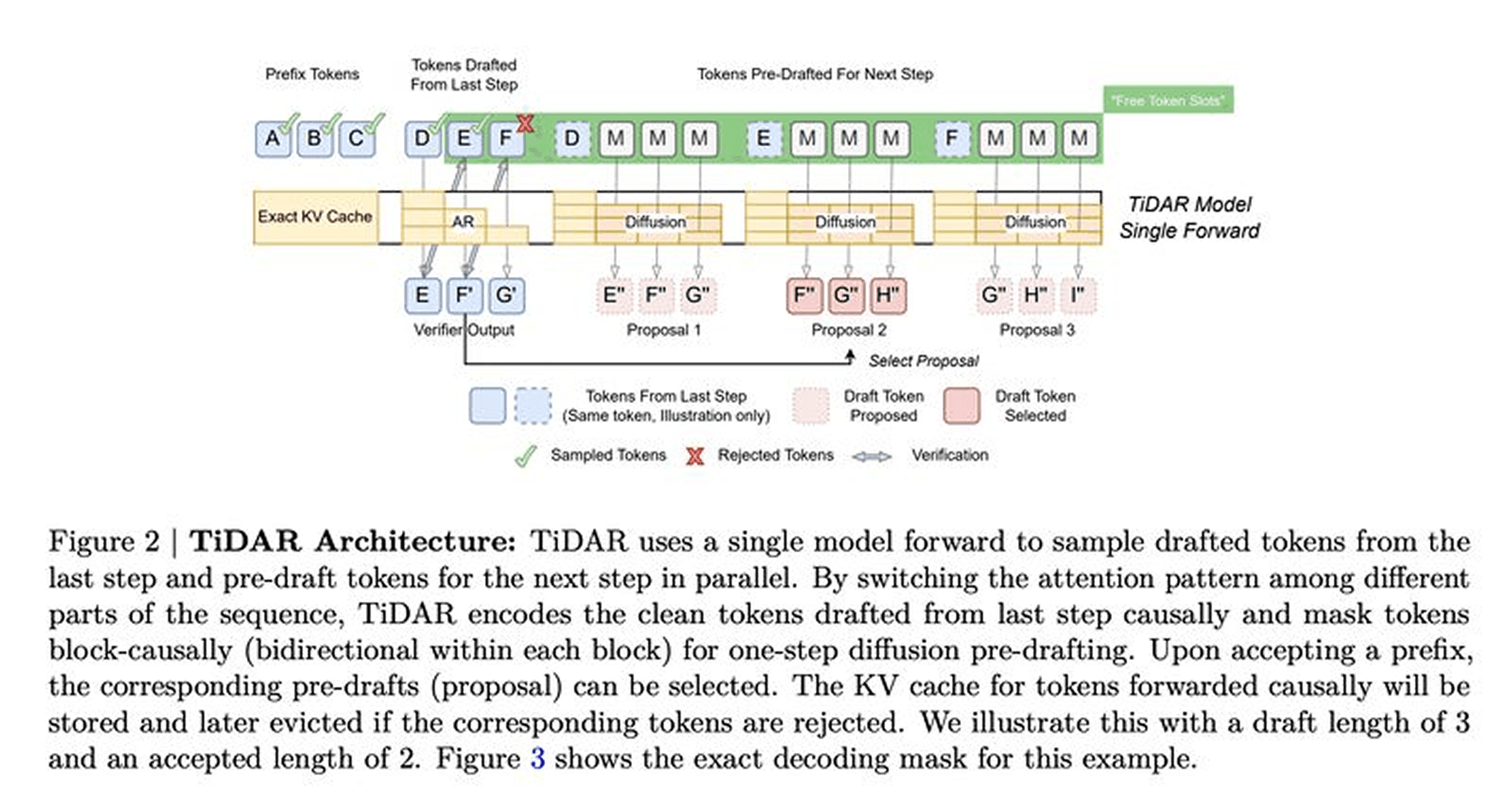
NVIDIA researchers introduce TiDAR, a hybrid text-generation architecture that merges diffusion-style parallel drafting with autoregressive decoding — both executed in a single forward pass.
Key findings:
Diffusion + AR in one pass:
TiDAR uses structured attention masks to run diffusion drafting and AR sampling simultaneously. It drafts multiple tokens in parallel from the marginal distribution while AR selects final outputs via rejection sampling, using otherwise idle GPU memory bandwidth to parallelize “for free.”
Speed without quality loss:
Achieves 4.71× (1.5B) and 5.91× (8B) speedups over standard AR models while maintaining competitive text quality. Produces 7–8 tokens per forward pass, outperforming speculative decoding (e.g., EAGLE-3) and prior diffusion generators on coding and math tasks.
Simplified training:
Uses full masking for diffusion during training, providing dense loss signals and straightforward AR–diffusion loss balancing. This supports one-step diffusion drafting at inference time with minimal complexity.
TiDAR shows a practical path to faster high-quality generation by combining the strengths of diffusion and autoregression rather than trading one for the other.
Read the TuesdayPaperThoughts analysis
Looking Forward
This fortnight’s updates point to a clear direction: frontier AI is moving from raw capability toward durability, autonomy, and real-world resilience. Models are becoming better long-horizon planners, more reliable operators of software, and more deeply embedded in national and enterprise infrastructure.
The parallel rise of sovereign AI conversations shows that the question is no longer whether AI will power critical systems—but how nations and companies ensure those systems remain secure, dependable, and adaptable. With faster decoding methods, smarter aggregation techniques, and agentic platforms maturing, the next phase of AI will be defined by stability as much as scale.




