
Welcome to Edition 5 of Fine-Tuned by Genloop – your go-to guide for the latest in LLM customization. This edition is packed with exciting model releases that are reshaping the AI landscape. We dive into Qwen's impressive QwQ-32B reasoning model that is 20x smaller than DeepSeek R1 with comparable results, DeepSeek's infrastructure innovations and upcoming R2 model, Microsoft's edge-friendly Phi-4 series, Anthropic's contentious Claude 3.7, and OpenAI's underwhelming GPT-4.5 launch.
Notably absent from the recent flurry of releases? Meta's Llama models which remain the most widely used foundation for enterprise domain intelligence. While they're making incremental improvements with reinforcement learning (SWE-RL paper, covered in Research Section), we're all waiting for Meta to make their next big move!
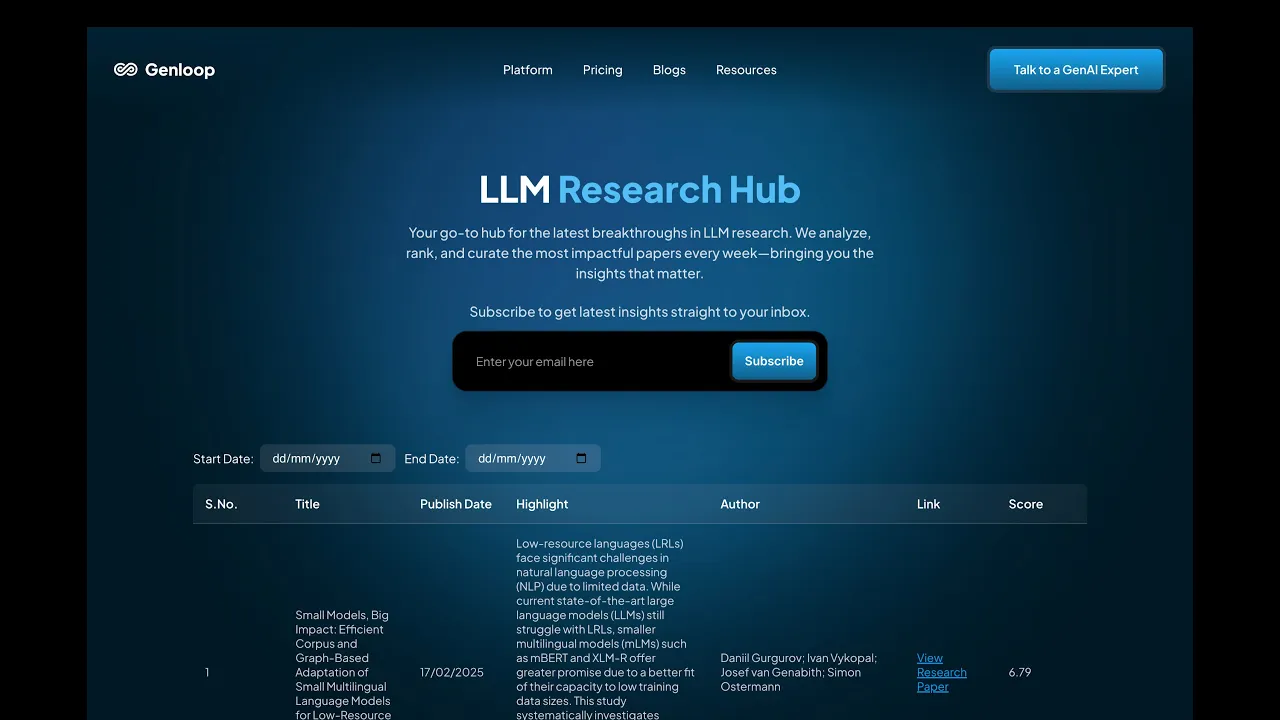
We're thrilled to announce the launch of our LLM Research Hub, where you can discover curated research papers ranked by popularity, relevance, and quality from multiple sources. We've also kicked off a weekly LLM Research Reading Group to collectively explore groundbreaking research – fill up the form if you're interested! (more about it in Genloop updates below)
Let's dive in!
🌟 AI Industry Highlights
Qwen Releases QwQ-32B Reasoning Model to Rival Industry Leaders
Qwen has launched QwQ-32B, a medium-sized reasoning model that achieves competitive performance against larger models like DeepSeek-R1 671B and outperforms OpenAI's o1-mini on several benchmarks despite having significantly fewer parameters.
Key points:
Efficient Architecture: Dense 32.5B parameter model (31.0B non-embedding) with 131k token context length, 20x smaller than DeepSeek R1!
Dual Training: Combines both Supervised Fine-Tuning (SFT) and Reinforcement Learning
Open Access: Available via Hugging Face and QwenChat with comprehensive documentation
This is just the medium model, their max model is still in development. Open-source is really pulling ahead in this race!

Source: https://huggingface.co/Qwen/QwQ-32B
Satya Nadella Grounds AI Hype with Economic Reality Check
In a surprising development, Microsoft CEO Satya Nadella has taken a pragmatic stance on AI's potential impact, focusing on economic benchmarks rather than superintelligence hype. This is quite contrary to OpenAI’s narrative. He suggests that the true measure of AI's success should be its contribution to GDP growth.
Key points:
Economic Benchmark: For AI to match the Industrial Revolution's impact, we'd need to see GDP growth jump from the current 2% to 7-10% in developed economies. That should translate to an additional $10 trillion in economic value annually
No Single Winner: Nadella also explained why he believes that no single company will dominate AI through one superior model, as open-source competition will prevent a "winner-take-all" scenario
Nadella directly challenges OpenAI's "universe value capture" investment thesis.
Claude 3.7 Sonnet Receives Mixed Reviews from Developers
Anthropic has released Claude 3.7 Sonnet, their most advanced model to date and the first "hybrid reasoning model" with extended thinking capabilities. While it is impressive on paper, the reception among developers has been surprisingly mixed, particularly regarding its coding abilities.
Key points:
Extended Thinking Mode: Claude 3.7 can show its reasoning process before answering, with user control over thinking depth
Claude Code Tool: A new command-line tool allowing AI to search codebases, edit files, run tests, and push to GitHub
User Complaints: Power users report issues with over-designing (400-line scripts ballooning to 1,100 lines), selective hearing of instructions, personality downgrade, and poor handling of complex projects
Adaptation Required: Successful users report better results by front-loading detailed instructions rather than conversational back-and-forth, being extremely specific about constraints, and starting fresh projects instead of continuing existing work
While this trend suggests advanced models may be trading collaborative flexibility for autonomous efficiency, having a leading closed-source model disappoint users raises concerns about proprietary solutions. This serves as a reminder to those who believe general-purpose LLMs alone can solve Enterprise AI—domain intelligence remains essential for extracting real value from Generative AI.

Source: https://www.anthropic.com/news/claude-3-7-sonnet
GPT-4.5 Launch Underwhelms as Economics of AI Scaling Questioned
OpenAI released GPT-4.5, positioning it for "emotional intelligence" rather than reasoning power. The reception has been decidedly mixed, more leaning on the negative side.
Key points:
Marginal Improvements: Former OpenAI researcher Andrej Karpathy noted it required 10X more compute for "diffuse" improvements
Prohibitive Pricing: At $75/input and $150/output per million tokens, GPT-4.5 costs 10-25X more than competitors
Economic Reality Check: With an estimated $500M training cost and plans to spend significantly more in 2025, the economics are increasingly questionable
Scaling Concerns: AI researcher Gary Marcus called it evidence that "scaling data and compute is not a physical law."
GPT-4.5 encapsulates the AI industry's current dilemma: delivering technological achievements that can't justify their astronomical costs. As one observer summarized: "Half the TL saying it's bad and too expensive. Half the TL saying it's good and too expensive." With Sam Altman declaring they're "out of GPUs," this release indicates the limits of scaling laws and price drops.

Source: https://x.com/sama/status/1895203654103351462
DeepSeek Releases AI Infra Effort, Races for R2 Model
DeepSeek has open-sourced some of their impressive infrastructure optimizations like the 3FS file system that gives 6.6 TiB/s throughput in a 180-node storage cluster. Reports also suggest it is rapidly approaching the R2 model.
Microsoft Unveils Phi-4 Small Language Models for Multimodal AI
Microsoft released Phi-4-multimodal (5.6B size) and Phi-4-mini (3.8B size), compact language models designed for edge deployments. The 5.6B parameter model can handle speech, vision, and text simultaneously, while the 3.8B parameter mini-model focuses on text-based tasks like reasoning, math, and coding. Read the release blog here.
✨ Genloop Updates: Introducing the LLM Research Hub
We're excited to announce the launch of our LLM Research Hub – a powerful tool designed to keep you at the cutting edge of language model research without the overwhelming information overload!
Keeping up with the latest LLM research has become increasingly challenging, with new papers published daily across multiple platforms. To solve this problem, we built an internal agentic workflow that automatically:
Gathers research papers from multiple authoritative sources
Ranks them based on relevance, quality, and potential impact
Curates the most significant findings for easy consumption
What began as an internal tool has now been opened to everyone!
We've also started a weekly paper reading group where we collectively dive deep into the most impactful research. If you'd like to join these sessions and stay at the forefront of LLM advancements, sign up using this form.
📚 Featured Blog Posts
We've got two fascinating reads that showcase how the AI landscape is evolving:
AI is rewriting our world - literally
Research reveals that AI is transforming written communication at an unprecedented pace. By late 2024:
18% of financial complaints show AI assistance
24% of corporate press releases involve AI writing
15% of small company job postings demonstrate AI influence
After ChatGPT's release, a brief adoption lag was followed by explosive integration across communication domains. Detection remains challenging, with sophisticated AI outputs often escaping current screening methods.
The implications are clear: AI is quietly but fundamentally reshaping how we write and communicate professionally.
GPT-4.5 is a nothing burger!
Despite significant anticipation, OpenAI's GPT-4.5 release has been described as underwhelming by many in the AI community. As Gary Marcus and others have pointed out, this release reveals several important trends in the current AI landscape.
Key points:
Diminishing Returns from Scaling: Traditional model scaling approaches are showing reduced effectiveness in improving performance
Competitive Landscape Shift: OpenAI is rapidly losing its dominant edge
Price-Performance Concerns: GPT-4.5 is 15x pricier than GPT-4o and 25x more expensive than Claude 3.7 Sonnet while offering similar or worse performance
Quality Inconsistency: Not every OpenAI release is delivering breakthrough capabilities
🔬 Research Corner
Our team has been diving deep into groundbreaking research papers, and two particularly caught our attention:
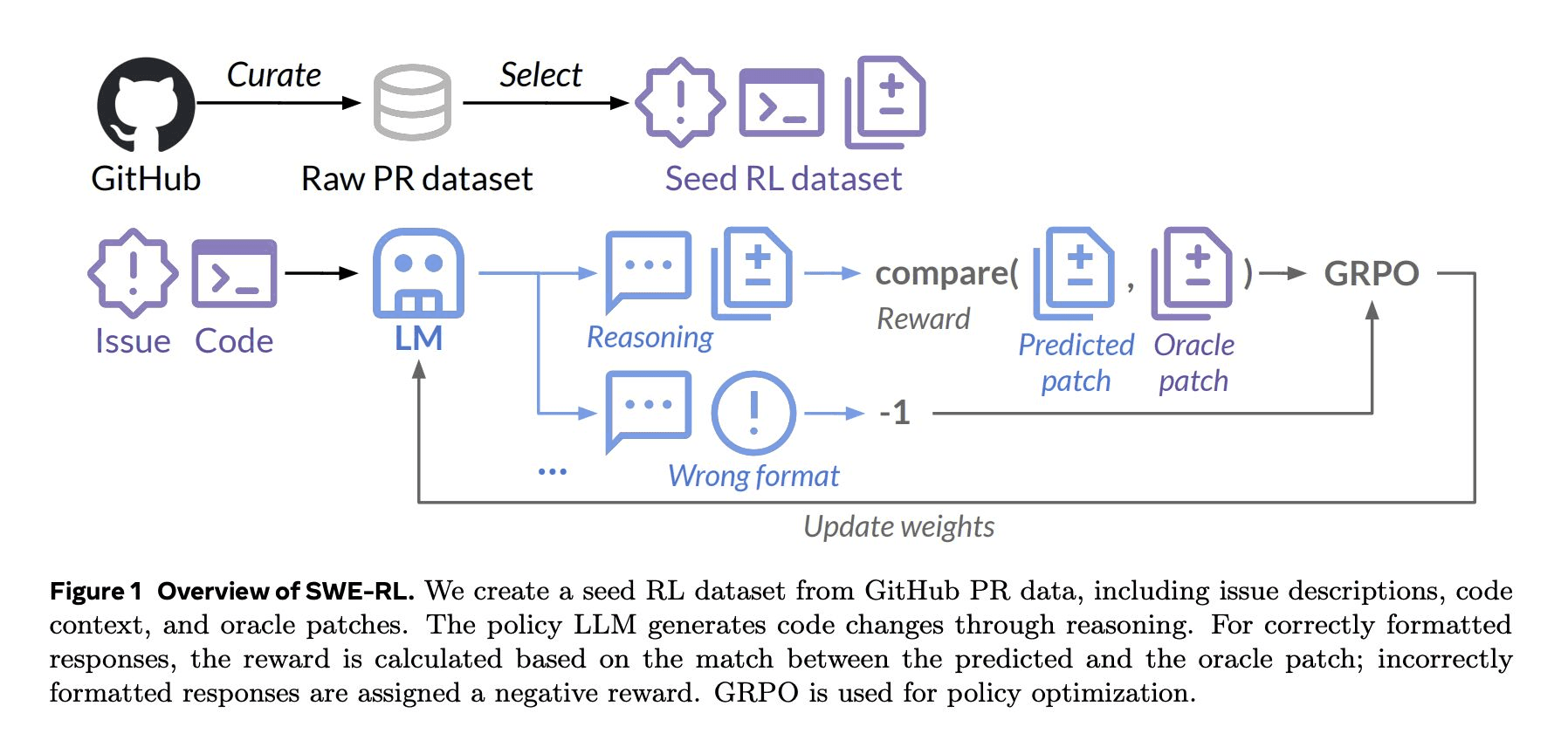
SWE-RL: Applying RL-Based Reasoning to Software Engineering
Meta AI's SWE-RL paper applies a GPRO-like approach (similar to DeepSeek R1's methodology) to fine-tune Llama 3 using open-source software evolution data. The result is a model that develops autonomous reasoning processes similar to those of experienced developers.
Key highlights:
Rule-Based Rewards: The model trains using reinforcement learning with rewards based on how well AI-generated fixes match verified software patches
Competitive Performance: Llama3-SWE-RL-70B solves 41.0% of issues on SWE-bench, matching much larger proprietary models like GPT-4o and outperforming other <100B models
Generalized Reasoning Benefits: Although focused on software tasks, the model unexpectedly improved at general reasoning, outperforming supervised fine-tuned baselines on five unrelated tasks
Read our TuesdayPaperThoughts analysis
NSA: Efficient Long-Context Modeling from DeepSeek AI
DeepSeek AI's NSA (Natively Sparse Attention) paper introduces a novel sparse attention mechanism designed for efficient processing of long sequences. This approach addresses one of the most significant challenges in scaling next-generation LLMs by reducing the computational burden of attention mechanisms.
Key highlights:
Hierarchical Sparse Strategy: NSA dynamically compresses and selects tokens, combining coarse-grained compression with fine-grained retention to maintain global context while reducing computation
Impressive Performance: The model matches or exceeds Full Attention baselines while achieving 11.6x, 9x, and 6x speedups in decoding, forward, and backward propagation, respectively
Hardware-Optimized Design: Unlike other sparse methods, NSA is designed for modern accelerators like A100 GPUs and can be trained end-to-end, reducing pretraining costs
With models now routinely handling 64k+ tokens, approaches like NSA become critical for making long-context reasoning both practical and efficient.
Read our TuesdayPaperThoughts analysis

Looking Forward
Open source is advancing rapidly, democratizing access to AI intelligence. While recent weeks have seen more breakthroughs coming from China than the US, this dynamic may shift soon—there are high expectations for Meta. DeepSeek's success has certainly given them a wake-up call.
This surge in competition has been transformative for open-source LLM development. We now have multiple specialized models—both reasoning and non-reasoning—that can outperform general-purpose LLMs. In fact, our own experiments with customized reasoning models are showing remarkable results, with performance improvements of 200% compared to leading general-purpose models like GPT4o. We'll be sharing these experimental findings in the coming weeks.
If you'd like to join our exclusive LLM Research Reading group, please sign up here. All papers that we'll be discussing will be available on our LLM Research Hub.
Thank you for reading! Share your thoughts with us, and don't forget to subscribe to stay updated on the latest in LLM customization.



