
The context
A leading analytics solutions provider in the life sciences industry helps pharmaceutical companies run their commercial operations: territorial planning, incentive management for market reps, target tracking, and revenue performance insights.
As they built out the next generation of their product suite with conversational intelligence, the tooling couldn't keep up with the complexity of the questions their clients needed to ask.
In pharma, that's not just a performance problem. Miss a single compliance condition, like surfacing sales data for a physician enrolled in the American Medical Association's Physician Data Restriction Program, and the exposure runs into billions in fines.
The problem
Their existing system was built on PowerBI. When they tried to go further with it, letting sales reps and commercial teams ask questions in plain English and get answers backed by real data, they ran into structural limits.
The questions their clients needed answered spanned territorial performance, incentive tracking, and revenue insights across complex, multi-system data. None of it was simple. Each question required applying business rules and compliance conditions that varied by physician and geography.
Their existing tooling couldn't handle that load reliably.
First attempt: query-banking on a RAG architecture
Before bringing in Genloop, the team built their own conversational layer. The architecture followed a common enterprise AI pattern: a retrieval-augmented generation system that matched incoming questions to a library of pre-written SQL examples, then used an Autogen-based agentic orchestrator to execute queries until one succeeded.
The system worked in a narrow band. On questions it had seen before, accuracy hit 90%. On new questions, that dropped to 76%. Four bottlenecks compounded into a serious problem:
Scale. Every new question type required a documented example in the vector database. Onboarding a new pharma client meant at least 2 months of engineering effort to build out the semantic layer from scratch.
Accuracy. The system pattern-matched on surface similarity, not conceptual understanding. Questions outside its documented scope failed hard. Business rules and compliance conditions were applied inconsistently.
Latency. Because the SQL writer frequently got it wrong on the first pass, the system had to retry. Average response time ran 25 to 35 seconds per query.
Cost. Each query averaged 10 LLM calls with expensive reasoning models. Cost per query settled at $0.60.
The approach itself was the constraint. The system was optimised for questions it already knew.
Bringing in Genloop
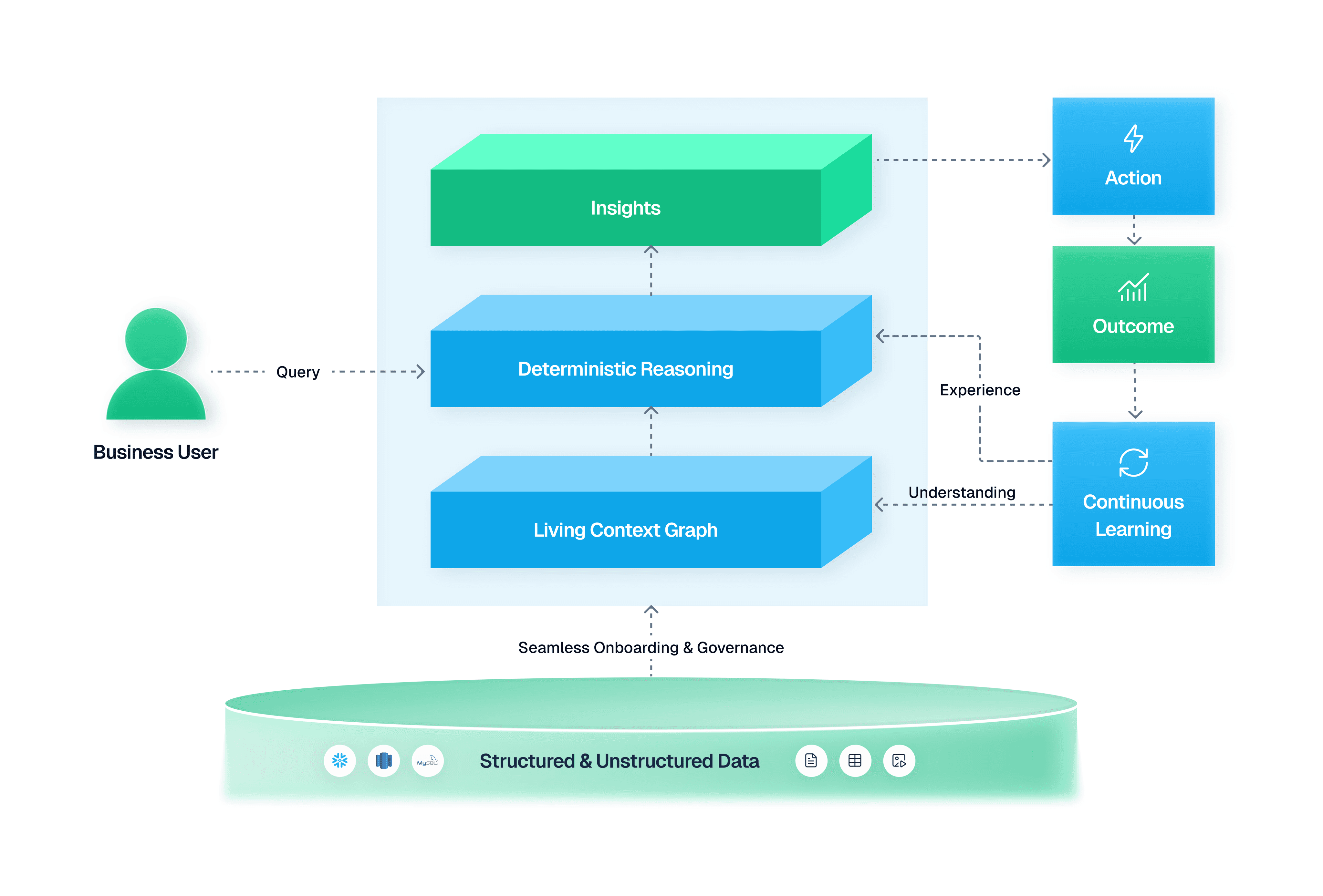
The team had their own agents and their own UI. What they needed was a context layer that could hold the complexity of pharma commercial data: the tribal knowledge, the compliance rules, the cross-system relationships that a static example bank couldn't capture.
Genloop sat underneath their existing stack, handling what their previous architecture couldn't. Three components:
Context Layer: A unified, structured representation of business logic and institutional knowledge that persists and evolves over time, not a static bank of examples.
Learning: Continuous improvement built in. Every interaction deepens the context layer rather than requiring manual updates to an examples library.
Governance: Compliance requirements like physician data restrictions handled automatically at the context layer.
Their own agents and UI stayed in place. Learn more about the Genloop architecture here
What changed
Metric | Before | After Genloop |
|---|---|---|
Overall accuracy improvement | Baseline | +22 percentage points |
Client onboarding time | 2+ months | Days |
Compliance rule application | Inconsistent | Automated at context layer |
Genloop automates compliance at the context layer.
Connect your warehouse and try it on your data.
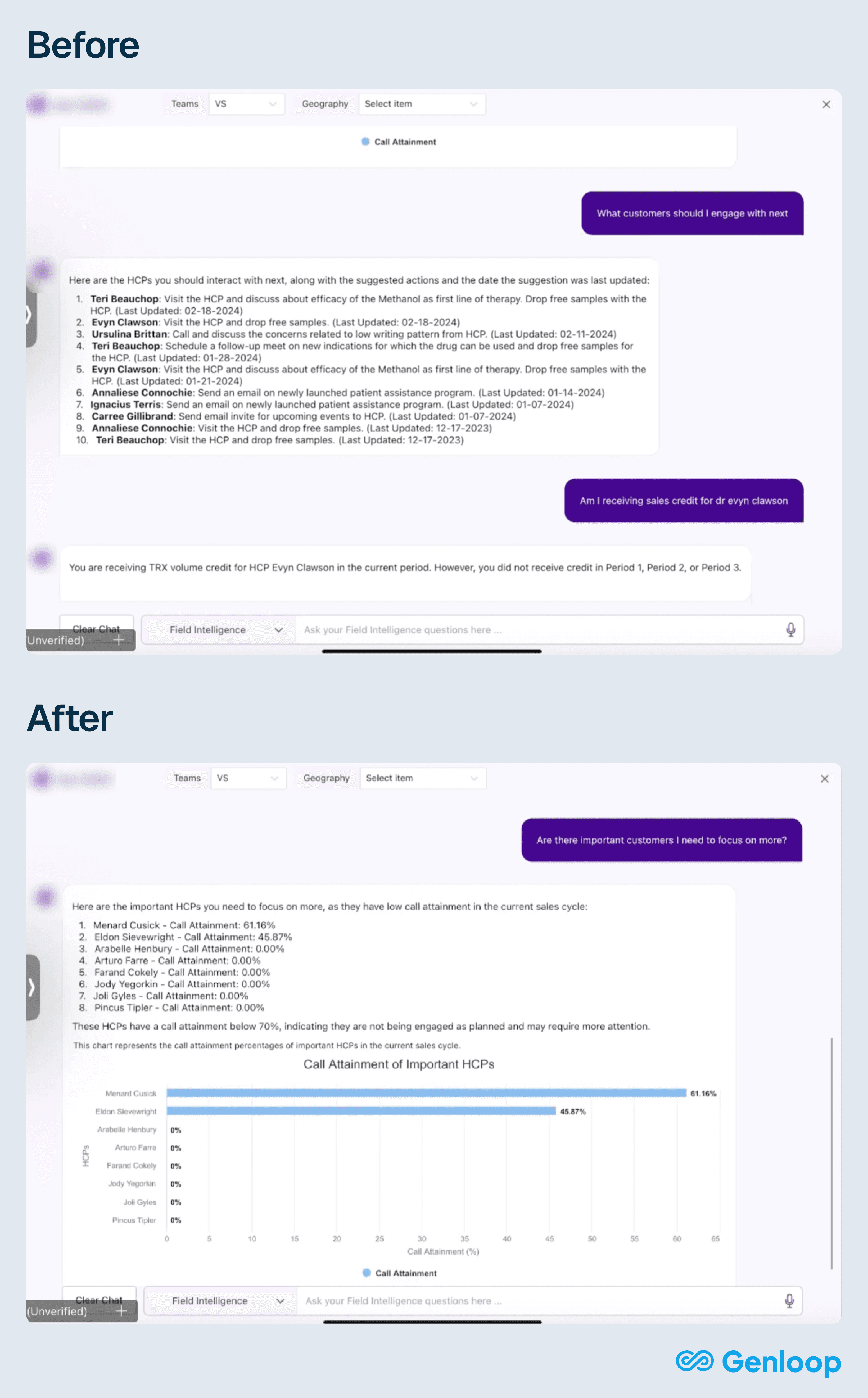
What teams could actually do after deployment
The system now handles complex, compliance-aware queries that were previously impossible:
Business impact
The accuracy jump matters, but the structural shift is what changes things. A system that learns means the cost of each new client question goes down over time. Onboarding that takes days instead of months means growth without a proportional increase in implementation effort.
For pharma clients, the compliance piece is the core of it. The old system applied business rules inconsistently because the rules lived in examples, not in context layer. Moving that logic into a governed context layer removes it as a recurring risk.



